Với ~q \ge 3~: ta nhận thấy số lượng ~N~ thỏa mãn sẽ là ~(10^{16}) ^ {\frac{1}{3}} (10^{16}) ^ {\frac{1}{4}} + (10^{16}) ^ {\frac{1}{5}} + \ldots \le 2 * 10^ 6~.
Vì vậy, hãy tính trước một mảng gồm toàn các số ~N~ thỏa mãn tìm được ~q \ge 3~ và tìm kiếm nhị phân trên đó để ra được số thỏa mãn.
Với ~q == 2~: ta cần kiểm tra ~N~ là số chính phương, mà không được dùng hàm sqrt cho sẵn -> sử dụng Binary search.
Đối với vùng (I), ta sẽ tính trước (sử dụng sàng) + tìm được tất cả các số nửa nguyên tố dựa vào khoảng tọa độ còn lại.
Đối với vùng (II), ta sẽ tìm tất cả số nguyên tố nằm trong đoạn [a, c], và tất cả số nguyên tố nằm trong đoạn [b, d]. Bạn đọc tự tìm công thức tính khi đã có được số lượng số nguyên tố ở hai vùng này.
Số lượng số nửa nguyên tố là tích của hai số trên, trừ đi cho số số nguyên tố nằm trên cả hai đoạn.
Ta lần lượt duyệt từ tấm ván thấp nhất lên cao nhất. Xét tấm ván thứ ~i~, ta sẽ tìm các tấm ván ~j~ với ~h[j] < h[i]~ mà Piccôlô có thể nhảy lên được tấm ván ~i~.
Để làm điều đó, ta xét các tấm ván lần lượt từ ~i-1~ đến tấm ván đầu tiên và duy trì khoảng diện tích ~A~ mà Piccôlô có thể nhảy đến tấm ván ~i~. Ta có thể xác định ~A~ bởi hai vector:
Vector bên trái bắt đầu từ điểm xa nhất của tấm ván ~i~ và đi qua điểm xa nhất của một tấm ván được lắp vuông góc với bức tường trái.
Vector bên phải bắt đầu từ điểm xa nhất của tấm ván ~i~ và đi qua điểm xa nhất của một tấm ván được lắp vuông góc với bức tường phải.
~A~ sẽ thu hẹp dần trong quá trình duyệt từ tấm ván ~i-1~ đến tấm ván đầu tiên.
Xét tấm ván ~j < i~, tại lúc này ta đã có hai vector được cập nhật dựa trên các tấm ván từ ~j+1~ đến ~i~. Nếu có ít nhất một điểm của tấm ván ~j~ nằm trong ~A~ (lưu ý là không nằm trực tiếp trên 2 vector) thì Piccôlô có thể nhảy từ tấm ván ~j~ đến tấm ván ~i~.
Trong quá trình duyệt ~i~, ta sẽ lưu phương án tốt nhất cho mỗi tấm ván ~i~.
Dựng mảng ~H~ có ~N~ phần tử, với mỗi phần tử là hiệu của hai phần tử tương ứng trong ~A~ và ~B~. Nói cách khác, với ~H_i = A_i - B_i~.
Với mỗi ~r~ thỏa mãn ~1 \le r \le N~, ta tìm phần tử ~l~ nhỏ nhất, sao cho GCD của các phần tử có chỉ số từ ~l~ đến ~r~ trong ~H~ không bé hơn ~2~.
Để tìm ~l~ nhanh chóng, đủ tối ưu để vượt qua time limit, ta có thể sử dụng các kỹ thuật khác nhau: Segment tree, RMQ, ... để có thể tính nhanh GCD của một đoạn trong ~O(log(n))~. Sau đó, binary search để tìm ~l~.
Đầu tiên, thử giải bài toán này với ĐPT ~O(N^2 * log(N))~.
Thay vì duyệt qua tất cả các hoán vị, ta sẽ muốn thử xem, với bao nhiêu hoán vị, mà nhãn ~i~ nằm ở vị trí thứ ~p~ trên cây, mà các phần tử trên đường đi từ gốc đến ~p~ tăng dần.
Kết quả là ~C(i - 1, h(p) - 1) * (n - h(p))!~, với ~h(p)~ là độ cao của node thứ ~p~ trên cây (quy định ~h(1) = 1~). Nếu ta tính trước các ~x!~ với mọi ~x \le n~, thì ~C()~ sẽ được tính trong ~O(log(10^9 + 7))~.
Tiếp theo, ta có thể đánh giá tiếp như sau để giảm độ phức tạp:
~\sum_{i = 1}^{n} C(x - 1, i - 1) = C(n, x)~
Có thể chứng minh trực quan sử dụng tam giác Pascal.
Đầu tiên nếu ~2K > N~: đặt ~x = min(K, N)~, xây dựng tập hợp hoán vị như sau:
~(1, 2, 3, \ldots, x | x + 1, x + 2, \ldots, N)~
~(2, 3, \ldots, x, 1 | x + 1, x + 2, \ldots, N)~
~(3, 4, \ldots, x, 1, 2 | x + 1, x + 2, \ldots, N)~
~\ldots~
~(n, 1, 2, \ldots, x - 2, x - 1 | x + 1, x + 2, \ldots, N)~
Dấu ~|~ được đặt ở giữa mỗi hoán vị chỉ đóng vai trò giúp các bạn hiểu ý tưởng xây dựng.
Luôn chứng minh được, với bất kỳ hoán vị độ dài ~N~ nào được sinh ra, ta có thể tìm được một hoán vị trong tập hợp này mà có ít nhất một vị trí trùng số.
Đối với trường hợp ~2K \le N~: ta sẽ chứng minh rằng không thể xây dựng tập hợp nào. Nói cách khách, với bất kỳ tập hợp nào có ~K~ hoán vị được sinh ra, luôn tồn tại một hoán vị mà vượt qua lớp hoán vị của cả ~K~ tập hợp đó.
Ta xét bài toán nhỏ sau, cho dãy số ~A~ có ~N~ phần tử (~1 \le N \le 2 \times 10^5~). Có ~q~ truy vấn, mỗi truy vấn có dạng ~l~, ~r~ và ~k~, tìm số các số từ trong dãy ~A~ từ index ~l~ đến ~r~ sao cho chia hết cho ~k~. (~1 \le l, r, k \le 10^5~)
Để giải quyết bài toán trên, ta làm như sau:
Đặt ~s = \sqrt 10^5~.
Chia 2 trường hợp
Nếu ~k \le s ~, ta có thể áp dụng ý tưởng prefix sum để tính toán từng truy vấn trong ~O(s)~.
Ngược lại ~k > s ~, gọi ~cnt(x)~ là số các số ~x~ trong đoạn ~[l, r]~. Duyệt các số ~p~ từ ~1~ đến ~s~, kết quả của truy vấn sẽ là ~\sum cnt(p \times k)~. Để tính ~cnt(x)~ trong ~[l, r]~ ta có thể dùng thuật toán Mo. Độ phức tạp mỗi truy vấn là ~O(s + \sqrt N)~.
Như vậy với bài toán trên độ phức tạp sẽ là ~O(q \times (s + \sqrt N ))~
Đối với bài toán gốc, ta có thể làm tương tự như vậy. Khi cắt một cạnh trên cây, cây sẽ chia làm 2 cây riêng biệt, nhưng cây con nằm dưới cạnh cắt thì có thứ tự dfs liên tiếp nhau, tương đồng với ~[l, r]~ trong bài toán trên. Sau đó có thể sử dụng phép bù trừ để tính giá trị của cây con còn lại.
Hoặc là ta có thể lưu giá trị ~k~ của các truy vấn vào các cạnh, và thực hiện tính toán khi dfs, như vậy thì sẽ không cần sử dụng thuật toán Mo.
Khi một viên gạch rơi xuống một hàng, nó sẽ được neo cùng với các ô thuộc hàng đó mãi mãi (nghĩa là tất cả các viên gạch thuộc hàng đó sẽ rơi xuống hoặc biến mất cùng nhau).
Nếu ta đánh chỉ số các hàng được tạo ra theo thời gian tăng dần, hàng xuất hiện sau luôn luôn ở trên hàng xuất hiện trước.
Lời giải:
Dựng cây segment tree để quản lý các cột.
Mỗi node của cây quản lý một đoạn ~[L, R]~, ta lưu tập các hàng ~S(L, R) = \{r_i, ...\}~ thoả mãn hàng ~r_i~ chứa mọi viên gạch thuộc các cột ~[L..R]~.
Chú ý rằng trong quá trình xây dựng và cập nhật cây, nếu một hàng ~r_i~ tồn tại ở cả 2 con ~left~ và ~right~ của một node ~par~, ta sẽ chuyển ~r_i~ lên lưu ở ~par~ và xoá ~r_i~ ở cả ~left~ và ~right~.
Như vậy cột ~j~ chứa hàng có chỉ số ~i~ khi và chỉ khi ~i~ tồn tại trong tập ~S~ của một node trên đường đi từ nút gốc đến nút lá quản lý cột ~i~.
Độ cao của một cột chính là độ cao của hàng có chỉ số lớn nhất thuộc cột đó.
Ở nút gốc, ~S(0, W-1)~ chứa tập các hàng mà sẽ biến mất khỏi bảng. Sau mỗi nước đi ta chỉ cần xoá các hàng này ở nút gốc.
Đánh giá:
Chi phí xử lý mỗi truy vấn thả gạch là ~O(f(N) \times g(N))~, với ~f(N)~ là độ phức tạp của thao tác cập nhật segment tree và ~g(N)~ là độ phức tạp của thao tác cập nhật trên mỗi tập ~S~. Với cài đặt persistent segment tree và persistent set bằng kỹ thuật path copy trên cây nhị phân cân bằng, ta đạt được độ phức tạp ~O(log^2(N))~ mỗi truy vấn.
Truy vấn rollback có chi phí ~O(1)~.
Chi phí bộ nhớ cỡ ~O(N \times log^2(N))~.
Ghi chú:
Lời giải được trình bày là online. Ta có thể có thuật toán hiệu quả hơn nếu làm offline (vì các truy vấn đã được biết trước).
Nếu đề bài không yêu cầu xử lý thao tác rollback, ta có thể giải bài toán với độ phức tạp tuyến tính (amortized ~O(1)~ mỗi truy vấn).
Mabư Béo đã rất vui sau khi được chứng kiến các bạn nhiệt tình giúp đỡ hắn ta trên hành trình tìm lại Bảy Viên Ngọc Rồng.
Thay mặt DTL và Mabư Béo, low_ xin cảm ơn đội ngũ VNOJ đã hỗ trợ cho contest được diễn ra. Cảm ơn các bạn thí sinh đã có màn trình diễn với những trận đua sôi động, và hẹn gặp các bạn ở trong các chuyến phiêu lưu tiếp theo! ^^
(Proposal đề được viết bằng tiếng Anh, các setter cũng chưa có thời gian để dịch lại đa số bài cho chuẩn. Mong các bạn thông cảm :D)
If ~N~ odd, the first kid that will exhaust of cookies are the one with the least amount of cookies to begin with. If there are multiple kids with the same number of minimum cookies, the kid with even indices will exhaust first, and then the odds. Then we'll consider whichever kid with the smaller index.
If ~N~ is even, only the even-indexed kid will be exhaust of cookies, as we can prove that the kid with odd index will have his number of cookies remain unchanged throughout the game. The smaller indexed kid will exhaust their cookies first.
~dp(i, k)~ - number of nodes that need rearrangement in subtree of root ~i~. ~k = true~ if ~i~ is parsed with one of its children, ~false~ if ~i~ is expected to be parsed with its parent node.
If ~i~ is a leaf (has only ~1~ connected node and not a root): ~dp(i, true) = 1~ and ~dp(i, false) = 0~.
For other ~i~: ~dp(i, true)~ and ~dp(i, false)~ will be calculated using ~dp~ information of their children.
~dp(i, true) =~ min of ~(dp(j, false) + ~ sum of ~dp(k, true)~ for every ~k \neq j)~ for every ~j~ is children of ~i~.
~dp(i, false) =~ sum of ~dp(j, true)~ for every ~j~ is children of ~i~.
~N~ is prime, can be written in ~3k + 1~. Therefore, ~N~ can also be written in ~6l + 1~.
For any ~N~, we will try to construct groups where (1) all groups have size ~2~, and (2) all groups have size ~3~. Then, we'll try to mash these 2 constructive algorithm together.
(1) Case of all ~a_i = 2~: For each ~i~ from ~1~ to ~\frac{N-1}{2}~, match ~i~ with ~N - i~.
(2) Case of all ~a_i = 3~. Set ~k = \frac{N - 1}{6}~. For each ~i~ from ~1~ to ~k~, we construct two sets: ~(i, 3k - 2i + 1, n - 3k + i - 1)~, ~(3k - 2i + 2, n - 2k + i - 1, n - k + i - 1)~.
Any greater ~a_i~ can be broken down into multiple smaller subsets of two above sizes. We just need to find a way to divide weights into sets of both types. For example, if you want to make a group of ~7~ weights, you just have to take ~2~ sets of size ~2~ and ~1~ set of size ~3~.
Base on the requirement, if you need to construct ~l_2~ groups of size ~2~, and ~l_3~ groups of size ~3~ (~l_2 * 2 + l_3 * 3 = N - 1~), here is one example of how you can construct these. The way I came up with these construction for ~N~ is that when I've already know how to construct groups of ~3~ for some ~N~, I can extend the same construction to ~N + 6~, and leave out some pairs to make group of ~2~:
Step 1: Set ~k = \frac{N - 1}{6}~ and ~l = \frac{N - l_3 * 3}{6}~.
Step 2: For each ~i~ from ~1~ to ~k - l~, create 2 sets of size ~3~: ~(i, 3 * k - l - 2 * i + 1, 3 * k + l + i)~ and ~(3 * k - l - 2 * i + 2, 4 * k + i, 5 * k + l + i)~.
Step 3: We can prove that if there exist some number ~i~ that unused after steps above, ~N - i~ is also unused. Therefore, unused numbers can be grouped into ~l_2~ groups of size ~2~.
Giả sử số bánh của mỗi đĩa trong đáp án là ~A_1, A_2, \ldots, A_N~. Đặt ~S_i = A_1 + A_2 + \ldots + A_i~, ta có ~A_N = M~ và điều kiện cần và đủ để thỏa mãn ~k~ vị khách là: với mỗi ~j \in [1..k]~, tồn tại ~i \in [1..N]~ sao cho ~S_i = \frac{jM}{k}~.
Do vậy, với mỗi ước ~k~ không lớn hơn ~N~ của ~M~, gọi ~G_k = \{\frac{M}{k}, \frac{2M}{k}, \ldots, \frac{kM}{k}\}~ thì điều kiện cần và đủ để tìm được dãy $A$ thỏa mãn tất cả các số ~P = \{k_1, k_2, \ldots, k_s\}~ là ~G(P) = |G_{k_1} \cup G_{k_2} \cup \ldots \cup G_{k_s}| \leq N~. Ta cần tìm tập ~P~ lớn nhất thỏa mãn điều kiện trên.
Ta có một số nhận xét sau:
Nếu dãy ~A~ thỏa mãn ~k~ thì dãy ~A~ cũng thỏa mãn mọi ước ~k'~ của ~k~. Do đó, nếu ~k \in P~ thì ~k' \in P~.
Giả sử ~P~ chứa tất cả các ước ~k' < k~ của ~k~ nhưng không chứa ~k~. Ta có ~G(P \cup \{k\}) = G(P) \cup G_k = G(P) \cup \{\frac{jM}{K} | 1 \leq j \leq k, gcd(k, j) = 1\}~. Suy ra ~|G(P \cup \{k\})| = |G(P)| + \phi(k)~, với ~\phi(k)~ là phi hàm Euler của ~k~.
Với ~k'~ là ước của ~k~, ~\phi(k') \leq \phi(k)~.
Bằng những nhận xét trên, ta có thể giải bài toán bằng thuật toán tham lam như sau:
Sắp xếp các ước ~k \leq N~ của ~M~ theo ~\phi(k)~ tăng dần, nếu bằng nhau sắp xếp theo ~k~ tăng dần.
Lần lượt thêm các ước vào tập kết quả ~P~ sao cho ~|G(P)| \leq N~.
Lưu ý rằng đề bài yêu cầu dãy gồm đúng ~N~ số nguyên dương, do đó, nếu ~|S| = |G(P)| < N~, ta cần thêm một vài giá trị vào ~S~ sao cho ~|S| = N~.
Ở các vị trí chẵn (đánh số từ ~0~), ~\texttt{a}~ thay bằng ~\texttt{abc}~, ~\texttt{b}~ thay bằng ~\texttt{bca}~, ~\texttt{c}~ thay bằng ~\texttt{cab}~.
Ở các vị trí lẻ, ~\texttt{a}~ thay bằng ~\texttt{cba}~, ~\texttt{b}~ bằng ~\texttt{acb}~, ~\texttt{c}~ bằng ~\texttt{bac}~.
If we put on a directed graph and connect from ~x~ to ~p(x)~, there will be some cycles. One application of ~p~ will move from one node to the node that it is connected to.
Assuming that there are ~k~ cycles with sizes ~C_1, C_2, ..., C_k~, the formula for ~G~ is:
~G(p) = LCM(C_1, C_2, ..., C_k)~.
The problem can narrows down to:
Given ~C_1, C_2, ..., C_k~. In one move, you can do one of these:
(1) Choose ~i~, ~j~: ~1 \le i < j \le k~, replace ~C_i, C_j~ with ~C_i + C_j~.
(2) Choose ~i~: ~1 \le i \le k~, replace ~C_i~ with ~C_k~ and ~C_l~ so that ~C_k + C_l = C_i~.
(3) Do nothing.
And your task is to minimize ~LCM(C)~.
Set ~\phi'(n)~ = ~\phi(\sqrt{n}) + \frac{\phi(n)}{64}~, with ~\phi(x)~ is the number of primes not greater than ~x~.
Now, for every number ~x~, we convert it to a vector (for primes ~\le \sqrt{n}~) + bitset (for primes ~> \sqrt{n}~) that can contain information of ~x~'s prime factorization. So now finding ~LCM~ of two numbers can be done for about ~\phi'(n)~ operations.
To faster calculate ~LCM(C)~ when we remove some numbers, we can use RMQ.
If we choose to do (1), what we can do is to iterate every pair that can be replaced. Since there can only be maximum of about ~\sqrt{N}~ different values in ~C~, every pair we can remove from the set can be checked in ~O(N)~. For each pair, to calculate new ~LCM~ would takes around ~5 LCM~ operations (with RMQ), so we can estimate that it would take about O(~\phi'(n)*N~) to discover all possibility for (1).
If we choose to do (2), we can for each value in ~C~ to find the best split possible for every value. In other words, for value ~x~, we can iterate through every ~y~ and ~z~ so that ~y + z = x~. We'll try to remove value ~x~ from ~C~ and replace it with ~LCM(y, z)~. Of course, if there are multiple copies of ~x~ in ~C~, we can skip ~x~ because it will not optimize ~LCM(C)~. Would also take about ~O(\phi'(n)*N)~ to discover all cases.
Overall complexity: ~O(N * \phi'(n))~.
Comparing to the intended solution above, we decided to lower the constraint from original version (5e4) to let more solution passed. As long as you conceptually understand the concept of having to find LCM, you can pass this problem easily!
Trước tiên, hãy thử giải phiên bản đơn giản hơn của bài toán: các tọa độ ~x_i~ và ~y_i~ đều phân biệt.
Xét một tập ~C~ những thành phố chưa bị chiếm trong một kế hoạch nào đó. Gọi ~(L, R, U)~ là những thành phố có hoành độ nhỏ nhất, hoành độ lớn nhất và tung độ lớn nhất trong các thành phố thuộc ~C~. Ta dễ thấy rằng:
Mọi thành phố ~(x, y)~ thỏa mãn ~x_L \le x \le x_R~ và ~y \le y_U~ đều thuộc C.
Mọi thành phố ~(x, y)~ không thỏa mãn điều kiện trên đều không thuộc C.
Do đó, mỗi bộ ~(L, R, U)~ tương ứng với tối đa một kế hoạch. Ngược lại, mỗi kế hoạch (trừ kế hoạch đánh chiếm tất cả các thành phố) tương ứng với đúng một bộ ~(L, R, U)~. Như vậy để đếm số kế hoạch, ta có thể đếm số bộ ~(L, R, U)~ tương ứng với một kế hoạch nào đó, rồi lấy kết quả cộng thêm ~1~. Điều kiện để bộ ~(L, R, U)~ thỏa mãn là:
~x_L \le x_U \le x_R~
~y_L \le y_U~, ~y_R \le y_U~
Vậy với mỗi thành phố ~U~, gọi ~left_U~ là số thành phố ~V~ thỏa mãn ~x_V \leq x_U, y_V \leq y_U~ và ~right_U~ là số thành phố ~V~ thỏa mãn ~x_V \geq x_U, y_V \leq y_U~ thì số kế hoạch sao cho ~U~ là thành phố chưa bị chiếm có tung độ lớn nhất là ~left_U \times right_U~. Ta có thể tìm ~left_U~ và ~right_U~ một cách hiệu quả bằng cấu trúc dữ liệu Fenwick Tree.
Trở lại với bài toán gốc, với mỗi tập ~C~ những thành phố chưa bị chiếm, ta cũng xét ~(x_L, x_R, y_U)~ là hoành độ nhỏ nhất, hoành độ lớn nhất và tung độ lớn nhất thuộc ~C~. Giống như ở trên, những thành phố nằm trong vùng bị giới hạn bởi những tọa độ trên đều chắc chắn thuộc ~C~, còn những thành phố nằm ngoài chắc chắn không thuộc ~C~. Tuy nhiên, những thành phố nằm "trên biên" có thể thuộc hoặc không thuộc ~C~. Do vậy, để tránh đếm lặp, với mỗi thành phố ~U~ ta sẽ đếm số tập ~C~ sao cho ~U~ là thành phố thuộc ~C~ có tung độ lớn nhất và có hoành độ lớn nhất trong những thành phố có cùng tung độ. Xét 4 trường hợp:
~U~ không nằm trên biên trái hoặc biên phải của ~C~. Ta gọi ~L_U~ là tập hợp (không rỗng) các thành phố nằm bên trái ~U~ trên biên của ~C~, và ~R_U~ là tập hợp (không rỗng) các thành phố nằm bên phải ~U~. Gọi ~left(U)~, ~right(U)~ là số tập ~L_U~, ~R_U~ thỏa mãn thì số cách chọn sẽ là ~left(U) \times right(U)~.
~U~ nằm trên biên trái nhưng không nằm trên biên phải của ~C~. Gọi ~D_U~ là tập hợp (có thể rỗng) các thành phố nằm dưới ~U~ và có cùng hoành độ với ~U~ trên biên của ~C~, và ~down(U)~ là số tập ~D_U~ thỏa mãn. Số cách chọn là ~down(U) \times right(U)~.
~U~ nằm trên biên phải nhưng không nằm trên biên trái của ~C~. Tương tự trường hợp 2, số cách chọn là ~left(U) \times down(U)~.
~U~ nằm trên cả biên trái và biên phải của ~C~. Trường hợp này chỉ xảy ra khi tập ~C~ gồm các thành phố có hoành độ bằng nhau, số cách chọn là ~down(U)~.
Cuối cùng, ta cần tìm cách tính ~left(U)~, ~right(U)~, ~down(U)~ với mỗi thành phố ~U~. Trước tiên, gọi ~low(x, y)~ là số thành phố nằm dưới tọa độ ~(x, y)~ (nói cách khác, số thành phố ~V~ thỏa mãn ~x_V = x~ và ~y_V < y~). Dễ thấy rằng ~down(U) = 2 ^ {low(x_U, y_U)}~. Tương tự, ~right(U) = \sum_{x > x_U} (2 ^ {low(x, y_U)} - 1)~. Việc tính ~left(U)~ đòi hỏi một chút kiến thức về quy hoạch động: xét ~U'~ là thành phố gần nhất về bên trái có cùng tung độ với ~U~. Ta có thể chọn ~L_U~ theo 1 trong 3 trường hợp sau:
Biên trái của ~L_U~ nằm bên trái ~U'~. Ta có thể chọn hoặc không chọn ~U'~ nằm trong ~L_U~, do đó số cách chọn là ~2 \times left(U')~.
Biên trái của ~L_U~ nằm dưới ~U'~. Tương tự trường hợp trên, ta có thể chọn hoặc không chọn ~U'~ nằm trong ~L_U~, do đó số cách chọn là ~2 \times down(U') - 1~ (không tính trường hợp ~L_U~ rỗng).
Biên trái của ~L_U~ nằm bên phải ~U'~. Do giữa ~U'~ và ~U~ không có thành phố nào cùng tung độ, biên trên của ~L_U~ chỉ chứa đúng thành phố ~U~. Do đó số cách chọn chính là số cách chọn biên trái: ~\sum_{x_U' < x < x_U} (2 ^ {low(x, y_U)} - 1)~.
Ta có thể tính nhanh những công thức trên bằng cách duyệt các thành phố ~U~ theo thứ tự tung độ tăng dần rồi hoành độ tăng dần, sử dụng Fenwick Tree để cập nhật giá trị và tính tổng một đoạn.
Because ~x~ and ~y~ are independent, the partial derivatives are easy to calculate.
We can then calculate all the local maximum / minimum, saddle points, .... Let's call these points of interest or POI.
Let's divide the world into a grid, with each POI being a point on the grid.
Then it's enough to do DSU on this grid, connecting each point that has height ~> c~ with a point adjacent to it on the grid.
Proof:
The proof has 3 part, first is proving that each region that is ~> c~ is represented by at least one POI:
From a point ~P~ that has height ~> c~, call ~S~ the set of points that is connected to ~P~ without going to any point with height ~\le c~.
It is clear that we can reach a local maximum of the whole function using this process:
Because the function is continuous, if ~P~ is not a local maximum, we can clearly go to an "adjacent point" with higher height.
Because at each time, we only go to a point with height height, we always stay above the height ~c~.
Thus every connected region of height ~> c~ contains at least one local maximum of the whole function, and can be represented by a local maximum.
The second part prove that the POI connected on the grid with height ~> c~ is in the same region:
Let’s ~A~ be a POI that has height ~> c~. Let ~B~ be another POI next to ~A~.
If ~B~ has height ~\le c~ then ~B~ is clearly not in the same region as ~A~. (It’s not in any region)
If ~B~ has height ~> c~ then ~B~ and ~A~ are clearly in the same region because on the direct path from ~A~ to ~B~, the function only increases or decreases (because between adjacent POI, the derivative is always positive or negative along an axis).
The third part proves that to go from a POI with height ~> c~ to another one with height ~> c~, it is always possible to just go through other POI.
Let’s draw a path ~> c~ connect to the ~2~ POI with height ~> c~.
Let’s say we move from one cell to another cell on the grid. We clearly cut through the shared edge between these cells.
Because each edge of a cell is increasing toward some direction, can move out path to end in one of the 2 POI that make up that edge that has height ~> c~.
So from the starting POI, we either move directly to an adjacent POI, or we move to the POI opposite on the same cell.
Due to property of POI, we can see that the diagonal move can always be changed to 2 adjacent move:
Assume diagonal move, then both point ~> c~
If no other POI ~> c~ then on one edge, we have increasing but on the opposite edge, we have decreasing
So from the starting POI, we can always move to an adjacent POI and still perverse the path.
Which means that it is possible to move from any POI to any other POI in the same region only through the POI graph.
Solving for the POI requires solving the 2 partial derivatives. For degree <= 3, this is just solving a quadratic equation.
Vào ngày thứ Bảy (19/11/2022) tới đây, chúng tôi, Dynamic Technology Lab, rất tự hào được đem đến cho cộng đồng VNOI cuộc thi DTL Algorithms Battle 2022!
Kỳ thi được tổ chức với mong muốn tạo sân chơi cạnh tranh lành mạnh cho các bạn lập trình viên, đồng thời giới thiệu với các bạn về các cơ hội làm việc với chúng tôi ở Dynamic Technology Lab Việt Nam.
Kỳ thi có 10 bài. Mỗi bài có giá trị 1 điểm. Bài sẽ chỉ được tính điểm nếu phần mềm bạn nộp chạy đúng tất cả các test theo như yêu cầu đề bài. Các bài đều không có subtask, cũng như không có điểm một phần.
Điểm của bài sẽ là điểm của lần nộp bài có điểm lớn nhất.
Các lần nộp bài trước lần nộp bài có điểm lớn nhất sẽ tính penalty 5 phút.
Các thí sinh bằng điểm sẽ được phân định bằng thời gian của lần nộp bài cuối cùng làm thay đổi kết quả (cộng với penalty).
Bảng xếp hạng sẽ công khai cho các thí sinh xuyên suốt 4 tiếng diễn ra cuộc thi.
Phần thưởng
05 thí sinh với màn thể hiện xuất sắc nhất trong cuộc thi sẽ được nhận các phần thưởng với giá trị tiền mặt như sau:
01 Giải Vô địch: 5.000.000 VND
01 Giải Nhất: 3.000.000 VND
01 Giải Nhì: 1.000.000 VND
02 Giải Ba: 500.000 VND
Ngoài ra, các thí sinh trên sẽ nhận được một gói quà, bao gồm tất cả các phần quà như dưới đến từ Dytechlab:
Áo T-shirt.
Túi rút thể thao.
Bút bi.
Sổ tay.
Stickers.
Các thí sinh có ranking từ 06-70 cũng sẽ được tham gia vào màn Bốc thăm may mắn như sau:
05 thí sinh may mắn trong các thí sinh có thứ hạng từ 06 đến 20 sẽ nhận được một set quà tặng bao gồm: Áo T-shirt, Bút bi, Sổ tay, Stickers.
10 thí sinh may mắn trong các thí sinh có thứ hạng từ 21 đến 70 sẽ nhận được một set quà tặng bao gồm: Túi rút thể thao, Bút bi, Sổ tay, Stickers.
Các thí sinh may mắn sẽ được phân định bằng đoạn mã C++. Quy tắc lựa chọn vui lòng đọc ở đây: https://pastebin.com/R1JJsswg.

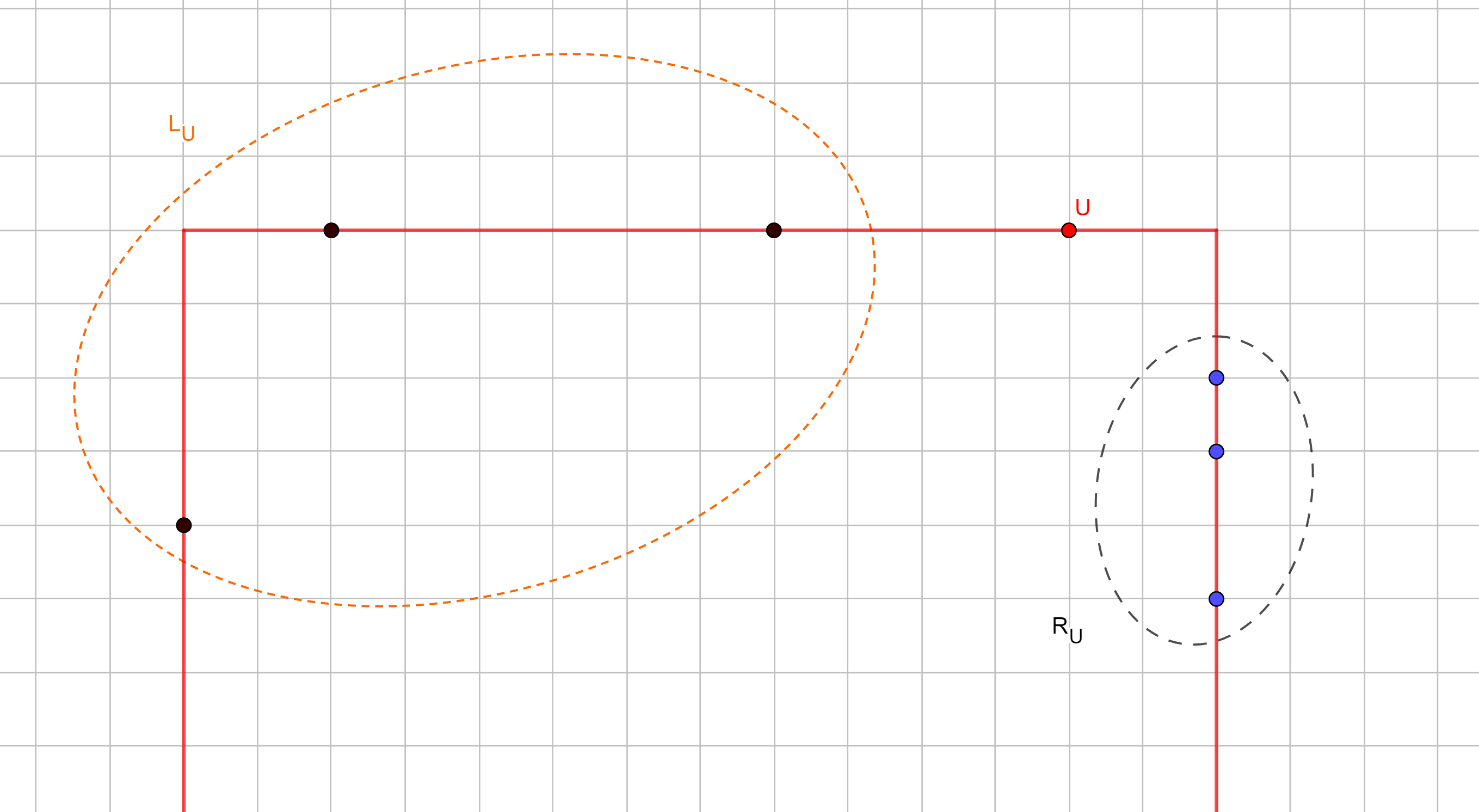 Ta gọi ~L_U~ là tập hợp (không rỗng) các thành phố nằm bên trái ~U~ trên biên của ~C~, và ~R_U~ là tập hợp (không rỗng) các thành phố nằm bên phải ~U~. Gọi ~left(U)~, ~right(U)~ là số tập ~L_U~, ~R_U~ thỏa mãn thì số cách chọn sẽ là ~left(U) \times right(U)~.
Ta gọi ~L_U~ là tập hợp (không rỗng) các thành phố nằm bên trái ~U~ trên biên của ~C~, và ~R_U~ là tập hợp (không rỗng) các thành phố nằm bên phải ~U~. Gọi ~left(U)~, ~right(U)~ là số tập ~L_U~, ~R_U~ thỏa mãn thì số cách chọn sẽ là ~left(U) \times right(U)~.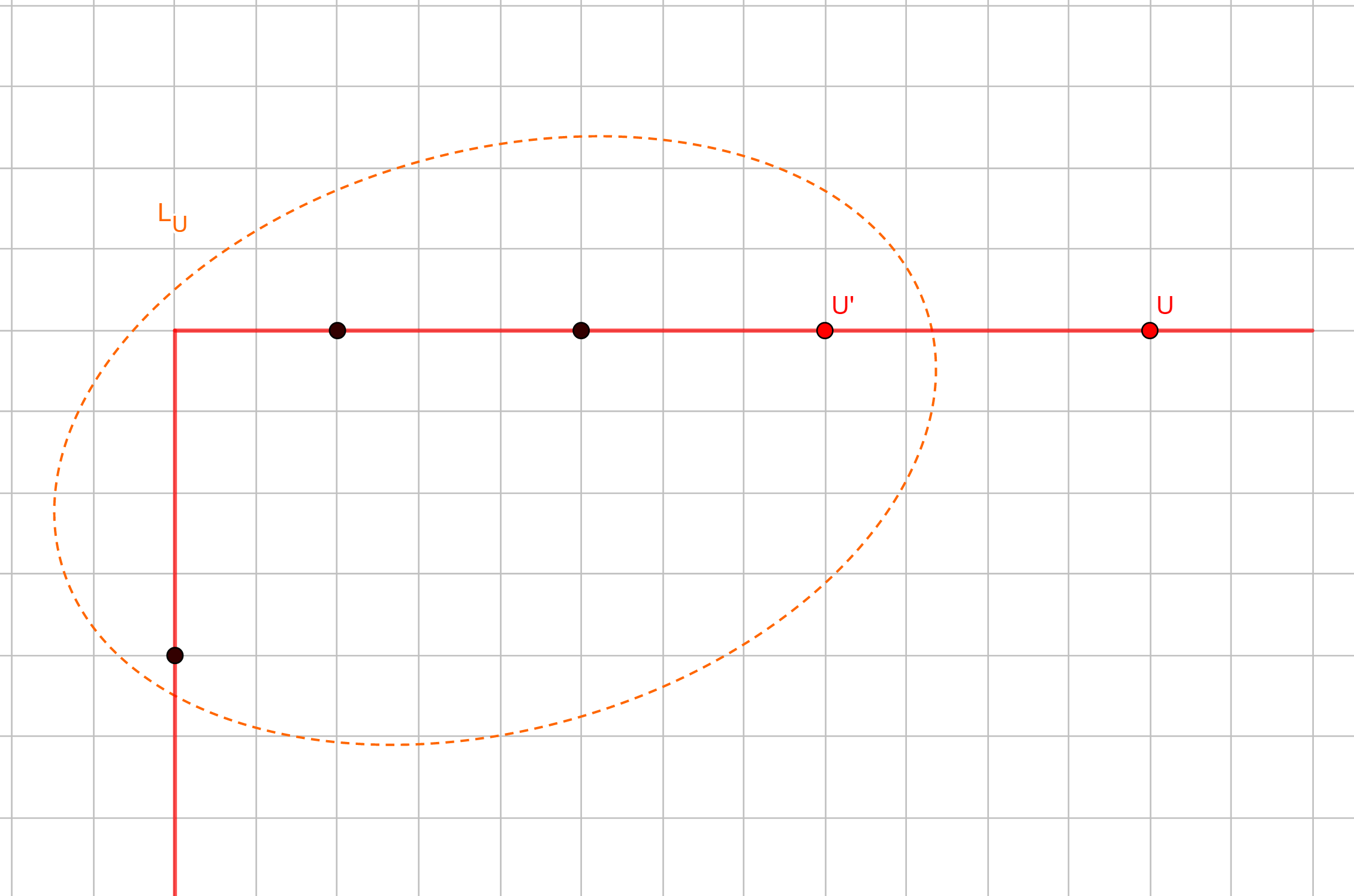 Ta có thể chọn hoặc không chọn ~U'~ nằm trong ~L_U~, do đó số cách chọn là ~2 \times left(U')~.
Ta có thể chọn hoặc không chọn ~U'~ nằm trong ~L_U~, do đó số cách chọn là ~2 \times left(U')~.

