Tạp chí VNOI số 2: Phỏng vấn Lê Kiến Thành
đã đăng vào 15, Tháng 5, 2026, 13:00Giới thiệu

Mình là Lê Kiến Thành, hiện tại đang là sinh viên năm nhất, trường Đại học Khoa học Tự nhiên, Đại học Quốc gia TP. Hồ Chí Minh. Trong năm vừa qua, thành tích tốt nhất của mình là Huy chương vàng Olympic Tin học Quốc tế (IOI) năm 2025 tại Bolivia.
Biên tập:
- Nguyễn Tấn Minh - The Chinese University of Hong Kong
- Nguyễn Trung Quân - Trường Đại học Khoa học tự nhiên, ĐHQG-HCM
Phỏng vấn
Tạp chí VNOI đã có cơ hội phỏng vấn khá nhiều bạn trẻ tài năng như Khánh Phúc và Huy Hậu. Cả hai em đều được tiếp xúc với Scratch từ độ tuổi rất nhỏ. Thành tìm được niềm đam mê với tin học thông qua điều gì? Ngôn ngữ lập trình đầu tiên mà Thành học có phải là Scratch hay không?
Mình tìm hiểu tin học khá là sớm từ những năm cấp một. Tuy nhiên, mình chỉ dừng ở mức nghịch qua thôi, không nghiêm túc tới mức đi thi Tin học trẻ như các em. Đến những năm cấp hai, mình vẫn làm những thứ “bựa bựa”, tạo ra một số Google Extension cho vui.
Đến những năm cấp ba, khi mình vào lớp Chuyên Tin, mình mới bắt đầu học Tin học một cách nghiêm túc.
Khi bạn mới bắt đầu, bạn có gặp một số khó khăn khi tiếp cận với Lập trình thi đấu hay không, đặc biệt khi xét về bối cảnh của Bình Định (cũ) - Gia Lai, vốn không quá nổi tiếng về mảng Tin học như các tỉnh thành khác?
Một trong những yếu tố lớn nhất mà mình phải nói chính là: với việc xuất phát từ môi trường như thế, vấn đề đầu tiên là mình sẽ bị “ếch ngồi đáy giếng”. Trong môi trường của tỉnh lúc đấy, giải ba cấp Quốc gia được xem như là cấp độ “thánh thần”, lâu lâu mới xuất hiện một lần. Như thế, mình dễ bị tự mãn, không biết mục tiêu của mình là gì và tiềm năng của mình đang ở mức nào.
Yếu tố thứ hai, các thầy cô cũng chỉ có kinh nghiệm chăm sóc và đào tạo học sinh đến một mức nào đó thôi. Ví dụ như lứa mình, cũng như là lứa kề trước là hai trong số những lứa vượt trội của tỉnh, có nhiều thành viên rất giỏi đạt được giải nhì, giải ba quốc gia. Trong khi các lứa trước thì chỉ ngang mức khuyến khích và giải ba thôi. Tuy nhiên, các thầy cô không có kinh nghiệm quản lý cho lắm, và mình thấy rằng đây là một điều khá đáng tiếc. Mình nghĩ rằng những lứa như mình đã có thể được quản lý tốt hơn: cho đi học trại, thỉnh giảng các thầy, v.v.
Khi vào chuyên Tin, bạn mới bắt đầu học Lập trình thi đấu một cách nghiêm túc. Khoảnh khắc mà Thành quyết định nghiêm túc với Tin học là khi nào? Quyết định ấy đến đột ngột, hay là nó từ từ hình thành trong bạn, sau khi cảm thấy rằng mình khá giỏi ở lĩnh vực này?
Thật ra, mình cũng không định hình được khoảnh khắc nào mà mình “Eureka!” với niềm đam mê Tin học, và sự gắn bó ấy đến từ từ với mình thôi.
Hồi trước, mình rất ghét YouTube Shorts vốn rất dễ gây xao nhãng. Thế là mình làm một quả tool cấm mấy trang web như thế luôn. Lúc mình làm Google Extension, ồ, mình thấy mình đẳng cấp quá, và cũng thấy được là Tin học khá là vui và hứng thú. Mình vốn định ôn vào chuyên Toán, nhưng sau đấy quyết định bỏ qua chuyên Tin.
Một khoảnh khắc đáng nhớ đối với mình trong những ngày đầu là lúc anh Phạm Bá Thái đến dạy tỉnh mình vào đầu năm lớp mười. Anh Thái cho những bài rất là Phạm Bá Thái, nổi bật là các bài toán “B bảo A mình không biết, A cũng bảo B mình chả biết gì, rồi B lại tìm ra được một số từ trên trời rơi xuống”. Từ những bài như thế, mình bắt đầu nghiệm ra được sự tuyệt vời của Tin học và dần dần nghiêm túc với Tin học hơn.
Bạn có bảo rằng sẽ vào chuyên Toán nếu như không học Tin. Bạn nghĩ rằng nếu vào chuyên Toán, bạn có thể đạt được niềm đam mê và những thành công với môn Toán như môn Tin hay không?
Dù nói rằng mình học để vào chuyên Toán, nhưng mình chỉ bắt đầu học từ năm lớp 9 thôi. Nên mình cũng không thực sự biết là liệu mình có gắn bó được với môn Toán lâu dài như với môn Tin không nữa. Mình cũng không biết được nếu mình vào chuyên Toán thì trình độ trần (skill cap) có được như môn Tin hay không. Nên là mình vui vì sự lựa chọn này của bản thân :D.
Theo dõi trang cá nhân của Thành, mình biết bố của Thành rất tự hào về Thành, cập nhật từng thành tựu của con. Gia đình của Thành trong những ngày đầu tiên học đội tuyển tỉnh Bình Định đã hỗ trợ, động viên Thành như thế nào?
Ba mẹ mình khá thoải mái, khá là ủng hộ mình. Tuy nhiên, cũng giống như hầu hết các bậc cha mẹ ở tỉnh lẻ khác, định hướng của họ sẽ mang tính truyền thống hơn - học lệch không tốt, phải học toán lý hoá vào, học đều lên, đừng chỉ học một môn, v.v. Nên là những ngày đầu, mình phải học nhiều một chút, đôi khi môn Tin còn phải học lén nữa.
Bởi vì đội tuyển là một hướng đi khá liều lĩnh với đa số các bạn.
Những thành tựu của bạn, như huy chương vàng IOI, rất là đáng kể. Khi bạn bắt đầu, bạn có đặt những mục tiêu “to” như vậy không? Bạn đã đặt những mục tiêu cụ thể nào khi mới bắt đầu?
Lúc mình mới bắt đầu học Tin học, mình còn không nghĩ là mình sẽ vào được đội tuyển quốc gia đâu chứ đừng nói là những thành tựu bây giờ.
Như mình đã nói, khi là “ếch ngồi đáy giếng”, mình không có góc nhìn tổng quát về tiềm năng của mình sẽ đi đến đâu và mình nên nhắm đến mức nào. Tiêu chuẩn của mình được nâng lên từng năm. Lớp 10 chỉ muốn có giải tỉnh, nhưng lại nhất tỉnh, thế là mong muốn được giải ba quốc gia, và mình được nhì quốc gia. Lớp 11, mình chỉ muốn vào vòng hai thôi, sau đấy lại vào được tuyển APIO.
Khoảnh khắc vào APIO là bước chuyển ngoặc. Là lần đầu tiên từ tỉnh lẻ ra biển lớn, mình được tiếp xúc với các anh, và nhận ra rằng “À, đây là trình độ đỉnh cao của Tin học”. Từ đấy, mình có động lực cày hơn, và đặt ra mục tiêu lớp 12 vào đội tuyển Quốc tế của Việt Nam.
Một ngày bình thường của Thành khi ôn thi Học sinh giỏi Quốc gia sẽ diễn ra như thế nào?
Cách học của mình sẽ thay đổi qua các năm, nhưng một mẫu số chung luôn được giữ vững chính là việc hạn chế làm các contests. Mình chỉ thích làm những bài riêng: mở Codeforces ra, tìm thấy bài hay và làm.
Mình cảm thấy việc làm một contest rất tốn năng lượng của bản thân, bởi vì mình phải liên tục cố gắng cho ra kết quả tốt nhất. Trong khi đó, với bài riêng, mình có thể làm khi não mình cảm thấy thong thả.
Vào thời điểm Offseason, mình sẽ học thoải mái hơn ở độ 5 tiếng mỗi ngày, vào mùa thi thì thời gian học có thể lên đến hai chữ số.
Khi bạn tự làm bài, những nguồn bạn chủ yếu lựa chọn là gì, ở trong nước hay quốc tế?
Mình chủ yếu làm nguồn quốc tế, bởi vì tiếng Anh của mình khá tốt. Cảm giác những bài quốc tế sẽ có sức nặng hơn - đề IOI tất nhiên đáng sợ hơn đề Việt Nam rồi.
Hai trang mình tập trung luyện chủ yếu là Codeforces và oj.uz. Năm lớp 10, 11, mình luyện hơi lan man nên nhảy rất nhiều nguồn, nhưng tới lớp 12 thì chỉ tập trung hai trang đấy thôi.
Như trải nghiệm của bản thân mình, việc nâng mục tiêu từ “có giải VOI” thành “vào vòng hai” là sự mơ hồ mà mình không thể hoàn toàn lý giải được. Thành đạt giải Nhì Học sinh giỏi Quốc gia ngay từ năm lớp 10. Với việc đặt mục tiêu lớn hơn cho năm lớp 11, xuyên suốt một năm sau đấy, bạn đã có chiến lược như thế nào để “đổi màu huy chương”?
Đấy chính là một phần đáng tiếc của mình trong chặng đường học tập. Bởi vì mình không có mục tiêu rõ ràng cho năm lớp 11, nên trình độ giữa năm 10 và 11 không chênh nhau nhiều. Trình độ của mình năm lớp 10 tầm 2000 Codeforces, tới năm 11 cũng chỉ lên 2100 thôi. Mình không có hướng học tập cụ thể, chỉ là mình có kinh nghiệm đi thi hơn, biết cách sử dụng trình stress test (lớp 10 mình còn không biết dùng sinh test, chỉ code đại đại xong được gì ăn nấy; lớp 11 chắc tay hơn nên được Nhất Quốc gia).
Khi vào vòng hai, điểm yếu đó đã bị lộ. Qua một năm luyện tập không có chủ đích, mình làm bài khá tệ và suýt soát mới vào được đội tuyển Châu Á Thái Bình Dương. Đến khi thi APIO, trình độ của mình lại bị lộ thêm một lần nữa khi mà mình đứng chót đội tuyển luôn. Sự đáng tiếc đấy chỉ ra một điều mà mình nghĩ rất là quan trọng, đấy là tầm nhìn về mọi thứ.
Từ trải nghiệm đáng tiếc ấy, Thành có lời khuyên gì cho những bạn có chung hoàn cảnh như Thành - được giải nhì và muốn có một “Last Dance” với đội tuyển Quốc tế?
Các bạn hãy thử nhờ các thầy cô cho các bạn tham gia những trại cao hơn - “Năm ngoái em được giải Nhì Quốc gia rồi, em nhờ thầy cho em tham gia một lớp dạy vòng hai”. Lúc đấy, mình sẽ tiếp xúc được với những cá nhân có trình độ cao. Mình biết được trời cao đến đâu, để mình sẵn sàng bay đến đấy.
Lời khuyên của mình: liên tục cọ xát, không được nghĩ rằng mình đã đủ giỏi rồi.
Thành đã làm hàng nghìn bài lập trình thi đấu. Quả bug nào là đáng “nhớ” nhất - làm bạn cay nhất, sai xàm xí nhất - mà Thành đã trải qua?
Một trong những bug mình cay nhất là bug tràn mảng. Với các bug khác, ví dụ như liên quan tới con trỏ, mình có thể biết được “à, tới đoạn này là nó bị crash, lặp vô hạn ở đâu đấy”. Nhưng tràn mảng thì sao? Khi mình chọn một giá trị, nó không báo lỗi, nó chỉ âm thầm sửa một giá trị khác, rất là khó đỡ. Những bug như này luôn ngốn mình nhiều thời gian nhất trong các kỳ thi, những quá trình làm bài.
Mọi người hay thấy một phiên bản Thành hướng ngoại tự tin hòa đồng đôi lúc hơi xàm xí tẹo. Nhưng liệu có khoảnh khắc nào trong hành trình mà bạn cảm thấy bị mất hứng, tiêu cực, muốn từ bỏ lập trình thi đấu và không muốn đẩy bản thân lên mức cao nhất có thể?
Nối tiếp lại câu chuyện hồi trước thì tất nhiên là có. Năm lớp 11, cả năm mình vẫn đứng lại ở trong mức trình Master Codeforces. Mình hay nghĩ với bản thân rằng nếu muốn đi tiếp, quãng đường còn xa quá. Khoảng cách từ một người tham gia APIO tới một bạn vào IOI vẫn quá xa. Sau cả một năm, mình vẫn chẳng thu hoạch được gì cả; giờ mà thêm một năm nữa cũng để làm gì đâu?
Sau đó, mình đã vận động bản thân bình tĩnh lại, cũng như phân tích mọi thứ và bắt đầu thay đổi cách học một chút. Và kết quả là mình lên được rank GM (Grandmaster) trong vòng 3 tháng.
Thành có nhận xét như thế nào về cách luyện tập ôn thi của các bạn hiện nay, xoay quanh rất rất nhiều các cuộc thi thử - hay được gọi là preVOI? Là một người ôn thi VOI bình thường, mình không có thiện cảm với format này, còn ý kiến của một bạn overqualified như Thành sẽ ra sao? Tác động của các contests preVOI tới trình độ của thí sinh nói chung là như thế nào?
Với tư cách là một người đi thi VOI hai lần, mình nghĩ rằng preVOI là một phần quan trọng trong quá trình ôn luyện VOI. Tuy nhiên, mình không có thiện cảm lắm với phong cách này.
Tưởng tượng rằng luyện thi có hai giai đoạn: đầu tiên là chính mình nâng cao trình độ nền của bản thân lên, và thứ hai mới là nâng cao kỹ năng đi thi. Ví dụ, khi mình học tiếng Anh, nghe nói đọc viết, mình áp dụng trong đời sống hằng ngày, và khi gần đi thi mới là lúc để luyện các form, các dạng đề của kỳ thi. Tin học cũng như thế.
Trong thời điểm Offseason, mình phải tập trung nâng cao trình độ. Với những kỳ thi solo như VOI, APIO hay thậm chí là IOI, nó cần rất ít những kỹ năng đi thi - bạn chỉ vét các subtasks, kiểm tra xem code của mình đã đúng hay chưa, chưa đúng thì viết lại. Những kỹ năng ấy chỉ cần luyện một ít là okay.
Phần training kỹ năng đi thi chỉ quan trọng trong những kỳ thi team như ICPC. Các bạn VOIer cứ thi theo đúng format trong khi luyện tập bình thường sẽ rất lãng phí, bởi vì preVOI chán, hao tổn sức lực, và tự nhiên các bạn lại tự ngăn cản quá trình học của mình. Thay vì mình giải nhiều bài hơn, mình lại đi vào môi trường offline, phải viết stress test, viết code trâu, cắn từng subtasks một. Mình đang tốn gấp ba lần thời gian chỉ để làm mình mệt hơn, chứ thật ra chả thu lại được gì cả.
Thành có tham gia các đợt ôn tập trung - trại hè, trại đông, v.v không?
Thật ra là trong quá trình cấp ba của mình thì mình không tham gia cái trại hè, trại đông nào cả. Nói chung là nghe cũng hơi kiêu, nhưng mà bởi vì mình đạt Nhì VOI từ sớm nên là hầu hết các trại ôn tập trung thì mình cũng đã tự nghĩ là cái những gì các thầy dạy trong đó cũng dưới trình mình hết rồi.
Nhưng bây giờ nhìn lại thì cũng khá là đáng tiếc, bởi vì những trại hè đó rất là vui, và biết đâu mình sẽ được mở mang tầm mắt thì sao - lỡ khi ở đấy có những bạn rất khủng, nhưng mình sẽ không bao giờ biết được, bởi vì mình không bao giờ đi.
Kỷ niệm đáng nhớ nhất của bạn với đội tuyển tỉnh Bình Định là gì? Đồng hành cùng đội hai năm, bạn có cảm nhận gì về khoảng thời gian đó?
Trong quá trình ôn luyện VOI của mình, năm lớp mười rất là đáng nhớ, Bởi vì là mình có tận bốn tháng để mình học ôn VOI. Đội tuyển VOI lúc đó là cứ như gia đình của mình vậy, mình lên lớp học, cùng anh em đi ăn trưa - thực đơn chỉ có hai món: mì cay và bún đậu mắm tôm, ăn xong đi uống trà sữa rồi lại đua xe bên bờ hồ. Mình cũng tiếp xúc với các anh và học được thêm nhiều điều, suy nghĩ thêm về dự định tương lai của các anh.
Năm mười một, tỉnh cho đội mình thi khá trễ nên chỉ đi học thôi chứ không có đủ thời gian để gọi là thực sự hiểu nhau hơn.
Vòng hai ẩn chứa nhiều chủ đề thú vị cho các thí sinh. Có chủ đề nào khi bước vào vòng hai mà Thành không thích hay không - chỉ cần thấy là muốn đóng máy đi ngủ thôi?
Mình chủ trương “nhạc nào cũng nhảy”. Mình phải “ăn tạp” một tí, bởi vì các thầy cho dạng bài rất đa dạng, không chỉ xoay quanh cấu trúc dữ liệu như trong đề VOI. Mình phải luyện đều bài truyền thống, interactive, bài chạy 2-steps, multi-steps, cũng như là các kỹ thuật mã hoá.
Nhưng mà dạng mình sợ nhất đó chính là heuristics, bởi vì mình không hề luyện tập cho dạng này. Lý do chủ yếu mình ngó lơ dạng này là bởi vì heuristics hiếm khi ra thi - lần cuối IOI ra dạng này là năm 2017. Và việc học dạng này cũng khá là chán bởi vì mình chỉ vào tối ưu, sửa code, ít bài yêu cầu mình nghĩ ra một cái gì đấy hay hay, nói chung là chỉ mò mẫm thôi. Mình thầm nghĩ là “Ôi, lần cuối xuất hiện đã là 2017 rồi thì có ai quan tâm đâu”, và đến năm mình thi IOI thì nó ra lại thật. Quá hay.
Rất may là heuristics không đánh gục bạn =))))
Có lúc nào trong khi thi TST mà Thành cảm thấy mình đã đánh mất cơ hội tham dự APIO hay IOI của mình không?
À hồi năm lớp mười một thì mình về cơ bản là đứa gà nhất tuyển, nên là mình đã mình chưa bao giờ có hy vọng thì mình chưa bao giờ mình đánh mất hy vọng cả.
Nhưng năm lớp 12, sau khoảng vài tháng luyện có chủ đích, trình mình đã tăng rất nhiều, và mình cảm thấy tự tin về khả năng của mình. Nhưng vào vòng thi, mình bị đề cho ăn hành nên là cực kỳ sợ. Hoá ra đề khó thật, ai cũng bị ăn hành như mình nên mình khá an tâm. Và cuối cùng mình top 1 TST năm ngoái.
Trước mỗi kỳ thi, Thành có dành thời gian làm những hoạt động “tâm linh” một chút - đi chùa, thắp hương cho ông bà, v.v?
Trước những kỳ thi đó mình cũng có, nhưng cơ bản mình cũng không phải là một con người tâm linh cho lắm. Thắp hương chủ yếu cũng chỉ là để đáp lễ, thông báo ông bà mình lên đường đi thi thôi. Còn các tiết mục xin kết quả tốt, mình không làm bởi vì cảm giác như nó bị vụ lợi quá.
Thành có thể mô tả cho độc giả biết là góc nhìn của người tham gia kỳ thi có sự khác biệt nào so với mình ngồi ngoài mình xem bảng rank hay không?
Theo mình thì cái áp lực phòng thi nó vẫn là một cái gì đó rất đáng sợ. Nói chung cuộc đời là thế mà, nói thì dễ lắm nhưng mà bắt tay vào làm thì hiếm ai làm được. Mình xem các anh làm bài cũng vậy thôi. Mình thấy các anh làm điểm ít, thì khi vào phòng thi mình mới hiểu rằng đang có gì diễn ra.
Mình có năm tiếng để làm ba bài. Bài nào nhìn cũng ngon, cũng có triển vọng hết. Mình không thể nào chia đều năm tiếng cho ba bài, nhưng lỡ mình all-in nhầm bài thì “đi” luôn. Áp lực đó rất là kinh khủng, vì chỉ có năm tiếng và mình phải đưa ra lựa chọn đúng, và khi lựa đúng rồi vẫn phải giải quyết bài toán nữa. Cảm giác ấy rất là run, và những người ngồi trước bảng rank với các con điểm, không thi thì sẽ không thể hiểu được.
Năm 2025, Thành đứng top 1 trong hai ngày TST ở Việt Nam. Điểm thi TST năm ngoái so với năm nay (2026) thấp hơn đáng kể. Từ lúc ở trong phòng thi, Thành có thể cảm nhận được sự tự tin về phong độ của mình hay không? Bạn có tin rằng mình đang nằm trong top cao - top 5 chẳng hạn?
Khi bước ra khỏi phòng thi, mình khá tự tin là mình sẽ đạt được top 5, nhưng mình không tự tin vào việc mình vào top một. Bởi vì điểm thi mình thấp mà, ngày hai mình chỉ làm được 8x / 300 điểm thôi. Bạn phải hiểu rằng ngày hai của TST năm đó, bài nào nhìn cũng rất là ngon, nhưng điểm mình còn không đạt tới mức ba chữ số nên mình khá là nhụt chí. Hoá ra ai cũng “banh xác” như mình hết, nên mình cũng vui hơn một tí.
Phòng thi IOI thật sự có toả ra aura gì khác lạ không? Thành hãy đưa độc giả tham quan một chút đi.
IOI 2025, mình được thi ở trong một sân vận động. Đây là lần đầu tiên mà mình được đi thi ở một phòng rộng như vậy, nhìn thấy được nhiều người như thế cùng một lúc. Cộng thêm với cái độ cao 3000m của Sucre, Bolivia và nhiệt độ lạnh buốt, mọi thứ nó vi diệu một cách kỳ lạ.
Có một câu chuyện hài, khi mình vào phòng thi IOI, mình phát hiện ra rằng mình được vào ghế R18. Có vẻ như là nhiều anh em rất là thích ghế này, mình cũng chả biết tại sao. R18 có nghĩa là gì? Các bạn hãy like và comment bên dưới video ý nghĩa của R18 nhé!

Thành hay nói là mình chỉ giỏi cài bài “trâu bò” - theo mình hiểu là cần tay to, sẽ hơi khó tìm được những khoảnh khắc eureka cực kì tinh tế. Trong sự nghiệp lập trình thi đấu của mình, Thành tự hào nhất về bài nào mà mình đã giải được?
Trong sự nghiệp lập trình thi đấu của mình, mình khá tự hào về một bài mình giải được năm lớp 12, đó là bài Tin học Trẻ bảng C của tỉnh.
Như các bạn biết rồi, Gia Lai có thể gọi là một tỉnh vùng trũng, cho nên là mình vào phòng thi với tâm thế là đề bị sai! Trong năm đấy thì nhìn đề có vẻ như bị sai thật. Bài C là một bài dùng thuật toán DP L-R (Range DP) với độ phức tạp ~O(N^2)~, nhưng giới hạn của bài lại là ~N \leq 10^7~. Mình liền nghĩ rằng đề bài ghi sai rồi, cái này làm sao làm được. Sau đấy mình cũng vứt đề đó đi và không nghiên cứu gì nhiều.
Khoảng thời gian từ lớp 11 lên 12, mình bắt đầu lục lại ký ức và giải lại bài đấy. Mình nháp một hồi lại nghĩ ra Palindrome Tree khá là ảo.
Đấy là một khoảnh khắc Eureka quá là okayge.
Mình hay nghe Thành bảo chúng mình 2k7 già mất rồi, để mấy nhóc 2k10 (iykyk) ngồi lên đầu như cơm bữa. Trong quá trình ôn luyện chuẩn bị cho các kỳ thi khác nhau (APIO, IOI, etc.), Thành có nhận thấy sự khác biệt nào giữa các “thế hệ” đi sau, với độ tuổi bắt đầu cùng lập trình ngày càng nhỏ đi.
Theo quan sát của mình, mình không cảm thấy có sự khác biệt gì. Và đó là một điều đáng sợ nha. Bởi vì trình các em ngang hoặc hơn mình, mà lại thua mình tận hai tuổi, quá là ghê gớm.
Cảm nhận về lứa sau của mình cũng chỉ thế thôi. Các em còn nhỏ mà giỏi quá, trong khi ở cùng thời điểm thì mình chỉ mò mẫm từng bước một.
Sau thành công rực rỡ tại IOI 25, Thành nhập học Đại học Khoa học Tự nhiên TP.HCM (HCMUS). Việc được “nghỉ ngơi” bù cho hơn ba năm cùng lập trình thi đấu đỉnh cao làm bạn có cảm xúc gì đặc biệt không?
Cảm xúc đầu tiên của mình chính là cảm giác đã hoàn thành được một nhiệm vụ rồi. Bây giờ, mình đang bước sang một trang mới cho cuộc sống của mình. Mình đã theo đuổi CP (Competitive Programming) suốt 3 năm trời, và giờ là lúc mình tạm gác lại nó để lên đại học.
Mình bắt đầu được trải nghiệm những thứ khác, những điều mới mẻ hơn. Nói chung, mình đang tập trải nghiệm cuộc sống như một người trưởng thành thực thụ - tự học, tự giấy tờ, tự đi lại, v.v. Mình cũng cố gắng thay đổi lối sống lành mạnh hơn. Như hồi cấp 3, mình chỉ học, học và học, vì dù gì mình cũng chỉ là một đứa trẻ thôi. Nhưng bây giờ là người lớn, mình đã có trách nhiệm với sức khỏe của bản thân. Mình cũng gọi là đã tới tuổi bắt đầu bị trì trệ rồi, đi lại xương khớp cũng sột soạt, nên cần phải để ý đến bản thân nhiều hơn. Và đó là ấn tượng của mình về năm gap-year này.
Nói ngắn gọn, năm nhất giúp mình định hình cách vận hành như một người lớn bình thường.
Là một sinh viên năm nhất không bình thường lắm, bạn có cảm giác gì khi đi học đại học mà ai cũng biết mình? Việc làm người nổi tiếng có gì thú vị không?
Trải nghiệm học đại học của mình sẽ chia làm hai phần: học đại học có gì mới, và làm người nổi tiếng có gì khác lạ hay không.
Học đại học có khi còn thoải mái hơn cấp ba, bởi vì mình có free will mà, thích cúp lúc nào thì cúp. Mình là người lớn, mình phải tự chịu trách nhiệm cho những gì mình làm - mình cúp thì sẽ không học bài, và cúp học thì phải cố gắng học bù ở nhà thôi. Bởi vậy nên việc mình cúp cũng có trọng lượng lớn hơn.
Thật ra mình cũng không hẳn là người nổi tiếng cho lắm. Anh em gần gũi thì cứ chơi chơi thôi, còn ra gặp người lạ thì nếu không nói thì cũng chả ai biết là mình vàng IOI đâu, nên cứ nói chuyện bình thường thoải mái. Nói chung là mình cũng không quan trọng những details này lắm.
Đạt được những thành công lớn ở cấp bậc phổ thông là bước đệm lớn cho tương lai. Thành nghĩ rằng tấm HCV IOI đã, đang, và sẽ có ảnh hưởng gì tới dự định tương lai? Thành nghĩ như thế nào về sự thoải mái mà nó đem lại - những cơ hội chu du đây đó, giảng dạy tại các trại hè, lớp học thêm, v.v?
Mình nghĩ là Huy chương vàng IOI hiện tại rất là nhiều lợi ích. Ví dụ như là bạn apply trường nào thì tỉ lệ đậu cũng sẽ rất là cao, được đi dạy trại hè (với giá cắt cổ) (hehe). Cơ bản, làm IOI-medalist có rất nhiều lợi thế, không chỉ về cái danh, mà còn là về tư duy mà mình đã được mài dũa vào năm cấp ba.
Nhưng mình cũng từng nghĩ, à, mình không được chủ quan, tự mãn quá. Về dự định tương lai, mình không có kế hoạch gắn bó với đi dạy đâu, vì mình cảm thấy việc đi dạy khá là chán. Nó chỉ vui được một tháng đầu tiên khi mà mình chuẩn bị nội dung, còn những tháng sau, mình cứ lặp đi lặp lại một kịch bản đấy thôi mà. Với quả CV IOI thế này, mình nên chú trọng hơn vào những mảng thế mạnh của mình liên quan đến giải thuật.
Thành sẽ đại diện HCMUS tham gia ICPC World Finals năm nay. Team bạn có đặt mục tiêu nào cho vòng chung kết lần đầu cũng là lần cuối (với HCMUS)?
Thật ra thì mình cũng không có mục tiêu gì lắm cho World Finals lần này.
Hai teammates của mình giờ cũng đã hơi ngán rồi, và mình đặc biệt cũng khá ngán CP rồi. Mình đã phải dí hai bạn để team luyện thi APAC mà. World Finals là kỳ thi cuối cùng, mà đã là kỳ thi cuối thì còn mục tiêu nào nữa. Với APAC thì mục tiêu là đậu WF, còn WF thì còn mục tiêu nào khả dĩ hơn nữa? Mình có huy chương thì khó quá. Với kỳ thi cuối cùng, mục tiêu của mình khá là mơ hồ nên mình nghĩ là bọn mình sẽ không nhắm cao quá đâu.
Tình trạng hiện tại của team mình, nếu vẫn giữ được nhịp độ từ APAC, có thể đâu đó đạt được top 20-30. Tuy nhiên, mình vẫn muốn hoàn thành tâm nguyện thầm kín của mình, đó là rank 36 World Finals năm nay.
Cả ba thành viên của ThaiFamily đều là những cá nhân có thành tích nổi bật của nền lập trình thi đấu Việt Nam - vốn chú trọng kỹ năng cá nhân. Cả ba bạn đã phối hợp với nhau như thế nào để dung hòa, phát huy hết điểm mạnh của đội trong các kì thi National, Regional và APAC vừa qua?
Qua những lần thi trước, team mình cũng rút ra được vài điều về điểm mạnh yếu của mỗi thành viên. Nhưng mà teamwork của bọn mình khá là bựa. Bởi vì cả ba người đều là những bạn có thành tích cao trong nền CP Việt Nam, tuy nhiên, vẫn có khoảng cách khá lớn giữa mình và hai bạn còn lại. Ở phần đầu kỳ thi, bọn mình sẽ phân chia ra ba người thôi, bởi vì mình tin rằng những bạn đó có thể làm được những bài dễ, vì dù gì các bạn cũng ở upper-Master tier trên Codeforces rồi mà. Sau đấy, vào giữa contests, đội mình sẽ chia thành đội hình 2-1, mình sẽ giải một bài, và hai bạn kia là một đội tấn công bài khác. Hai người nghĩ bài sẽ dễ hơn, nhưng ba người nghĩ cùng một bài sẽ rất lãng phí. Cuối contests thì quay về đội hình 3 người cùng nghĩ truyền thống.
Thêm một phần nữa cũng khá bựa trong kỳ thi APAC vừa rồi, đó chính là những bài nào mà mình thấy hay thì mình làm, còn những bài nào mình thấy casework kinh quá thì sẽ vứt qua cho anh em. Các bạn có vẻ không hưởng ứng lắm nhưng họ vẫn cứ làm thôi.
Và đó là lý do team bạn trong bốn tiếng đầu rất căng nhưng tới tiếng cuối cùng lại không làm gì?
Ba tiếng đầu tiên! Mình làm 3 tiếng đầu, 2 tiếng còn lại ngồi chơi.
Team ThaiFamily có sự gắn kết đặc biệt với thầy Phạm Bá Thái của HCMUS. Thành có thể cho mình biết sự liên kết ấy đến từ đâu không?
Team ThaiFamily đến với anh Thái vì những lý do khác nhau. Mình đến với anh Thái bởi vì anh là một trong những người kéo mình vào lập trình thi đấu. Vào một ngày đẹp trời vào tháng mười năm ấy, anh Thái đến như một vị thần cùng bộ bài ảo ma làm mình nổ não khi nhận ra vẻ đẹp của Tin học.
Anh Thái về cơ bản là một người khá hòa đồng cởi mở với các học sinh. Mình cảm giác anh Thái vừa có khí chất của một người thầy, nhưng cũng rất là thoải mái với sinh viên. Ngoài ra, anh cũng có một số khoảnh khắc, các loại content rất là thú vị: như là quả content rất nổi tiếng một tay ôm cả thế giới vào lòng - mỗi người chỉ ôm một thế giới thôi còn anh Thái ôm bốn thế giới.
Anh Thái có có đóng góp gì về mặt tinh thần cho cho team ThaiFamily trong hành trình đến với Dubai không? Trên fanpage của anh Thái, anh có bảo là hoàn thành được tâm nguyện mà anh Thái vẫn còn bỏ dở.
Anh Thái giúp bọn mình khá là nhiều trong quá trình ICPC. Anh hỗ trợ một chút về mặt tinh thần, dẫn cả đội đi ăn. Mình nhớ hồi bữa thi APAC, anh Thái thấy thực đơn có súp khai vị. Bọn mình đặt 4 súp khai vị và nó đưa ra bốn cái nồi lẩu bởi vì Google Dịch làm việc hơi í ẹ một tí. Anh Thái cũng thường xuyên chỉ về những wisdom của anh - chiến thuật cơ bản khi làm team (tản nhau ra để giải tỏa cho não của nhau, rồi sau đấy kết hợp lại theo đội hình, v.v.).
Tất nhiên anh sẽ không thân chinh đi train cùng bọn mình, nhưng về cơ bản, anh là một mascot rất là quan trọng của team!
Kết thúc hành trình lập trình thi đấu ba năm, mình khá chật vật trong việc tìm ra niềm vui thú mới, và cân bằng thời gian nghiên cứu và bài vở đại học. Từ khi trở thành người lớn thực thụ, Thành có cảm thấy FOMO, mất động lực, hay không biết làm gì tiếp theo lúc nào chưa?
Trong thời gian vừa qua, mình cũng hơi bị FOMO. Gap year này mình dành thời gian để khám phá thế giới của người lớn mà, chẳng có năng lượng để nghĩ về những điều khác. Nhưng mình nghĩ rồi mọi thứ chắc sẽ okay thôi. Dùng một năm thư giãn cũng không sao cả, không phải lúc nào mình cũng phải căng đâu. Năm này là năm mình tích lũy kinh nghiệm sống, ổn định lại tinh thần, cải thiện lối sống thì sẽ hay hơn. Nói chung là vẫn FOMO, nhưng không có hối hận về quyết định của bản thân hiện tại.
Hay nghe phong thanh bạn Thành chán Competitive Programming lắm rồi, chả luyện tập gì đáng kể từ khi vào HCMUS. Sự chán chường với niềm-vui-thú-một-thời bắt nguồn từ đâu? Và kỳ nghỉ hưu ngắn hạn dành cho Competitive Programming (không hẳn vì Thành vẫn thi ICPC) có ảnh hưởng thế nào tới đời sống học thuật của Thành không?
Nói chung là mình khá chán CP, bởi vì môn này là một môn mà bạn không nên luyện một cách căng thẳng trong một khoảng thời gian quá dài như thế. Lên Đại học, tất nhiên mình sẽ hơi xa lánh nó thôi. Ngoài ra, mình cũng có nhiều chuyện khác thế chỗ cho CP, khiến mình không bận tâm gì về sự vắng mặt của CP trong cuộc sống của mình. Bản chất là từ việc mình gắn bó quá lâu rồi nên bị chán và dễ bỏ hơn.
Kỳ nghỉ hưu ngắn hạn dành cho CP không ảnh hưởng đến cuộc sống học thuật của mình cho lắm, bởi vì mình vẫn còn những thứ khác để nghịch mà. Tất nhiên là sẽ không vui bằng CP bởi vì nó không kích thích não bộ cho lắm, nhưng nói chung là mọi thứ vẫn okela.
Thành sắp sửa nhập học Đại học Quốc gia Singapore (NUS). Bắt đầu một hành trình mới tại môi trường quốc tế, bạn có kỳ vọng gì về tương lai của mình hay không? Cánh cửa đại diện NUS tại ICPC World Finals có nằm trong tầm ngắm của Thành?
Về phần đại diện NUS tại ICPC World Finals, mình không có nguyện vọng gì lắm. Bởi vì mình đã đi WF một lần, tất cả thành tựu mình cũng đã có hết rồi, chỉ trừ huy chương ICPC World Finals. Mình cảm thấy mục tiêu đấy xa vời, và thật ra mình đã hơi chán, nên mình không muốn nhắm đến huy chương WF nữa.
Mình không có kỳ vọng gì hẳn hoi cho lắm cho tương lai. Bây giờ mình vẫn còn đang mơ hồ về con đường sau này.
Rất nhiều cá nhân tiêu biểu trong nền Lập trình thi đấu Việt Nam bắt đầu nghiên cứu, một số người theo các tập đoàn lớn, tham gia vào các hoạt động Quantitative Trading căng thẳng. Thành nhận thấy mình là người phù hợp với môi trường làm việc nào?
Hiện tại, mình nghĩ là mình sẽ thích môi trường làm việc hơn. Nghe nghiên cứu cảm giác khá chán, mình phải sống lại những gì mình đã làm ở cấp 3. Mình muốn đổi gió một tí, học một số skillset khác hẳn luôn.
Nếu bạn lựa chọn nghiên cứu, lĩnh vực nào sẽ thu hút bạn nhất? AI, lý thuyết, hệ thống, hay là một lĩnh vực khác hoàn toàn?
Nếu mình phải chọn, thì có lẽ sẽ là AI. Bởi vì AI là tương lai, nó sẽ xuất hiện ở khắp mọi nơi. Mình chỉ chưa chắc lắm về tương lai của AI thôi, nhưng những ứng dụng của AI bây giờ thì đã rất tuyệt vời rồi. Và nếu như mình là một phần của nó thì biết đâu sẽ tuyệt vời hơn.
Thành có suy nghĩ gì về những công việc giảng dạy gắn bó với lập trình thi đấu?
Giảng dạy lập trình thi đấu là một công việc rất là hiếm người. Dạy là một công việc rất chán, làm việc lại kiếm được nhiều tiền hơn, và một phần là nó vui hơn nhiều. Vì vậy nên hầu như không ai muốn đi dạy cả. Mình cảm thấy đây là một điều khá đáng tiếc.
Mình nghĩ là Việt Nam cần nhiều người dạy mảng này hơn. Các thầy cô ở các tỉnh hiện tại cũng không có kinh nghiệm lắm về việc dạy lập trình thi đấu ở mức độ cao - ở mức giải ba Quốc gia, hầu hết phải outsource cho các thầy nổi tiếng. Do vậy, mình không thể nào lan tỏa được những tài liệu, sự hay ho của lập trình thi đấu đến với “buôn làng”.
Với những thành tích đồ sộ, tiêu biểu là tấm huy chương vàng IOI, Thành nhận thấy rằng để trở thành một người thầy tốt, mình cần đặt ra những tiêu chuẩn nào cho bản thân?
Về tiêu chuẩn của một người thầy tốt, mình nghĩ rằng để trở thành một người thầy tốt, điều đầu tiên là phải liên tục cập nhật những kiến thức mới. Hồi mình học IOI, mình được gặp gỡ với anh Nguyễn Tiến Trung Kiên - Bạc IOI 2015. Anh Kiên thấy là mình AC bài Persistent Segment Tree không có cảm xúc gì. Anh hỏi thì mới biết được là Persistent Segment Tree đã trở thành kiến thức thường thức dành cho học sinh rồi, đến các bạn thi HSGQG cũng đã học hết rồi. Môn Tin học là một môn phát triển rất là nhanh. Cũng đúng thôi, bởi vì đây là một môn có tuổi đời bé hơn nửa thế kỷ, tiến hoá rất nhanh. Vì vậy, các thầy cô cũng phải có trách nhiệm thường xuyên cập nhật meta để biết được nên dạy cái gì.
Điều thứ hai, cũng là một yếu tố mà mình nghĩ anh Thái làm rất là tốt, đó chính là gần gũi với học sinh. Nhưng mà vừa phải gần gũi với học sinh, vừa cân bằng được việc thể hiện uy nghiêm của một người thầy. Về sự gần gũi thì mình cũng có mini stories. Mình có thử làm ra hai dạng contests cho các bạn học sinh. Contest đầu tiên có bộ đề rất bình thường, chỉ dài ba dòng với điều kiện và yêu cầu của bài, các bạn có vẻ không thích cho lắm. Hai contests tiếp theo được viết một cách chăm chút hơn, mình cho vào những nhân vật rất là nổi tiếng như là anh Độ Mixi, thầy Tú Sena, Thầy Giáo Ba, anh Bình Gold, v.v Thì các bạn có vẻ rất là hưởng ứng các nhân vật này, làm bài rất là căng. Mình thấy rằng số lượng người làm bài phải gấp ba lần những contests mà không có content như thế.
Ở một lớp khác, mình tạo 2 contests, một contest có anh Độ Mixi, một contest không có anh Độ. Contest thứ hai, học sinh không thấy anh Độ Mixi, học sinh réo mình hỏi “Anh ơi, anh Độ Mixi đâu rồi? Em muốn contest sau có anh Độ Mixi! Em nhớ anh Độ Mixi quá!”.

Việc mình gần gũi, nhưng vẫn thể hiện ra được rằng mình là một người “bề trên”, có kiến thức, có kinh nghiệm đó là một điều rất là cần thiết đối với một người thầy dạy lập trình thi đấu. Đặc biệt khi mà hầu hết lực lượng đi dạy CP đều là những con người rất trẻ tuổi - anh Hạnh năm nay 29 tuổi, anh Thái 31 tuổi, anh Hoàng tầm 32 tuổi, v.v.
Thành nghĩ rằng lập trình thi đấu trong tương lai sẽ phát triển theo xu hướng nào, và bạn có muốn là một phần của nó không?
Trong tương lai, lập trình thi đấu cũng sẽ giống như bây giờ thôi. Bởi vì giống như môn toán, bao nhiêu năm vẫn thế thôi, không có việc “toán kết hợp với AI’ bao giờ. Toán vẫn chỉ là toán, và lập trình thi đấu về bản chất vẫn như vậy thôi. Đây là bộ môn kích thích sự phát triển của bộ não con người, nên trong tương lai gần thì CP vẫn sẽ sống tốt. Chỉ có điều các quản trị viên online judges phải quản lý chặt các cheaters hơn một chút.
Mình biết một số bạn tự nguyện dành 100% cuộc sống của mình cho lập trình thi đấu. Lập trình thi đấu và đời sống cá nhân của Thành có được phân tách rõ ràng hay không?
Thực ra hồi năm cấp ba thì lập trình cũng là cuộc sống của mình: mình ăn và ngủ cùng với lập trình thi đấu mà. Kiểu như là có nhiều lúc, mình lên lớp cấp ba học, nhưng trước khi lên lớp, mình sẽ nhớ trong đầu ba đề lập trình thi đấu, rồi lên lớp mình giải. Các thầy cô thấy mình lock-in quá tưởng mình chăm học, nên các thầy cô khen mình dữ lắm, mà mình cũng không biết tại sao mình được khen.
Tuy nhiên thì đời sống cá nhân của mình, dù là một phần nhỏ, nhưng mà nó cũng tách biệt thôi. Ngoài lập trình thi đấu, mình vẫn sinh hoạt với các bạn khác bình thường - cùng các bạn đi chơi game, đi leo núi đi bida các kiểu.
Biết Thành cũng kha khá lâu, mình biết rằng Thành hoà đồng với mọi người, và khá vui tính. Có khi nào Thành cảm thấy mình hơi “kiêu ngạo” - ôi những chủ đề này thật tốn thời gian, sao không dành khoảng thời gian đấy đi học thuật toán đi??
Mình rất chú tâm vào CP, cơ mà mình sẽ không tới mức đó đâu. Mình là một con người rất thích học những thứ mới, nhiều lúc các bạn nói về những thứ hay ho thì mình cũng muốn học theo các bạn. Mình không bao giờ có những suy nghĩ kiểu “các bạn nói chuyện xàm quá, bây giờ mình muốn quay về nhà học thuật toán thôi”. Mình rất chú tâm vào CP, nhưng sẽ không tới mức đó đâu.
Trong thời gian rảnh rỗi, Thành thường thả lỏng bản thân bằng những hoạt động nào?
Hồi cấp ba, mình thường hay thả lỏng bản thân bằng những hoạt động như là chơi game, hẹn anh em ra uống trà đá tán gẫu, cầu lông, bida. Những hoạt động đơn giản thế thôi, cũng không có gì quá đặc biệt.
Đội tuyển IOI Việt Nam là một phần ký ức đẹp cho tất cả các bạn vinh dự là một phần của nó. Khoảng thời gian đấy, có ai - các thầy, các anh đi trước, đã để lại ấn tượng sâu sắc cho Thành?
Oke! Bây giờ mình sẽ nhắc đến một người anh, một người thầy có ảnh hưởng rất lớn đối với đội tuyển IOI. Đó chính là thầy Bảo - thầy Trương Văn Quốc Bảo, huy chương bạc IOI 2021 và 2022.
Thầy Bảo có tầm ảnh hưởng rất lớn với bọn mình, bởi vì thầy Bảo dạy cho bọn mình thế nào là học, và thế nào là chơi. Đã học thì phải học rất là căng, nhưng chơi thì cũng phải chơi tới bến! “Ăn chơi để biết vị đời” mà!
Mình rất là ấn tượng với khoảnh khắc thầy Bảo (Trương Văn Quốc Bảo, HCB IOI 2021-2022) dẫn anh em ra đi bida. Sau đấy thầy Bảo thấy em Hậu có vẻ như là không quen với bida cho lắm. Nên là thầy Bảo đi tới, và bắt đầu uốn nắn từng tư thế, từng cách thọc gậy của em Hậu. Và khoảnh khắc ấy làm mình rất là ấn tượng.

Vì sao bạn cảm thấy ấn tượng? Bạn ấn tượng vì điều gì?
Mình không ngờ là khi học đội tuyển IOI thì sẽ có những hoạt động “phản cảm” như thế này (cười). Thầy giáo đi chỉ học sinh từng đường gậy.
Anh Bảo rất là hài nha. Tưởng tượng sau buổi học, các em rủ anh Bảo đi chơi bida. Anh Bảo rút găng tay màu hồng từ trong túi ra. Anh em nhìn sợ té khói luôn. Hoá ra anh Bảo đã chuẩn bị sẵn sàng cho tâm thế đi bida, và anh đã tính trước cái này từ lâu lắm rồi!
Kỳ thi APIO 2026, chọn đội tuyển đi thi IOI 2026 cũng sắp diễn ra rồi. Các bạn có muốn gửi lời nhắn gì cho các em?
Thì mình có lời nhắc đó chính là: Các em hãy cứ cố gắng giữ gìn sức khỏe đấy. Các em đừng có đi nét xuyên đêm là một, các em đừng có trèo rào ra ngoài để mà đi uống sinh tố là hai, bởi vì là cái hàng rào giờ nhìn nó yếu lắm rồi. Nhìn điều kiện là không muốn trèo rồi.
Và ba đó chính là bây giờ các em hãy xem những thời gian này là một thời gian gọi là thả lỏng, và gọi là để biết được thêm về CP, chứ giờ này thì học nó cũng không có tác dụng gì nữa đâu. Mình đã học hết ba năm rồi mà, mình học thêm hai tuần nữa nó cũng không có tác dụng gì.
Nên là bây giờ là thời gian để mà mình biết là mình thả lỏng, nhưng mà đừng thả lỏng quá, mình thả lỏng thôi. Mình thả lỏng và mình gọi là cũng trải nghiệm, và mình enjoy cái quãng thời gian đi cùng anh em APIO như thế này.
Trong cuộc đời của mỗi con người, thành công luôn được định nghĩa bằng hoàn cảnh mà người đó đang trải qua. Thành công đối với Thành bây giờ là gì?
Thì nói chung là khi mà lên đại học thì nó không còn là một cái kỳ thi - mình không còn một cái kỳ thi lớn như IOI là một cái đến cuối cùng nữa. Mà đại học về cơ bản nói chung sẽ là nhiều cái quest nhỏ khác nhau ấy.
Ấy thì bây giờ là mình nghĩ thành công đối với mình là bây giờ là: một, đó chính là sức khỏe mình vẫn tốt. Và hai là là mình sẽ hoàn thành tốt nhiệm vụ học tập của mình và mình hiểu được hơn về thị trường làm việc và hiểu thêm về cuộc sống. Như thế mình nghĩ là thành công đối với hiện tại rồi.
Một lần nữa cảm ơn Lê Kiến Thành đã tham gia phần phỏng vấn cùng với tạp chí VNOI. Chúc bạn thành công trong hành trình mới ở Singapore, đạt được nhiều thành công hơn nữa! Thank you!






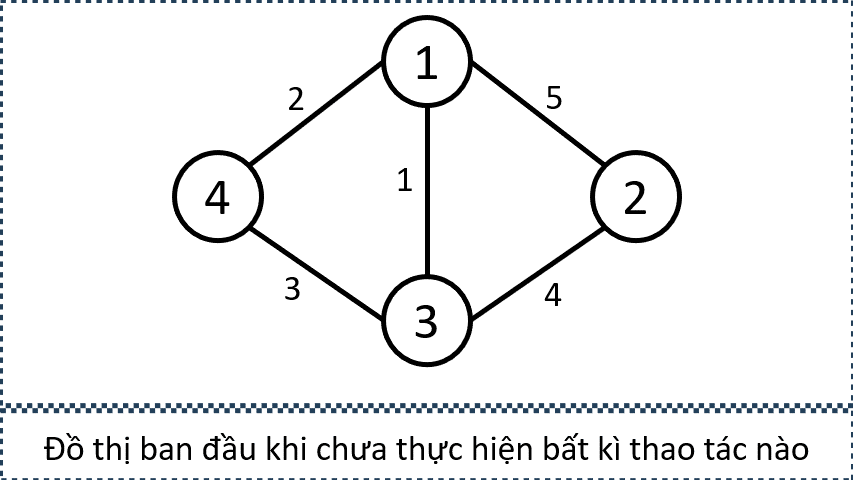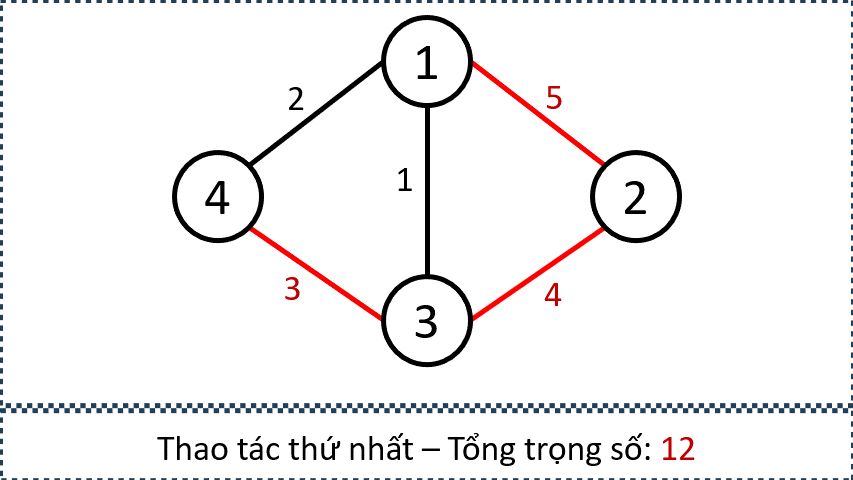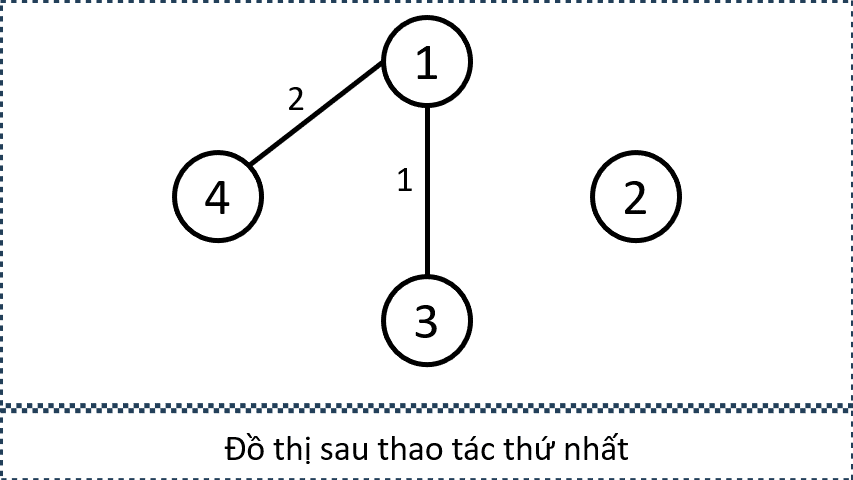
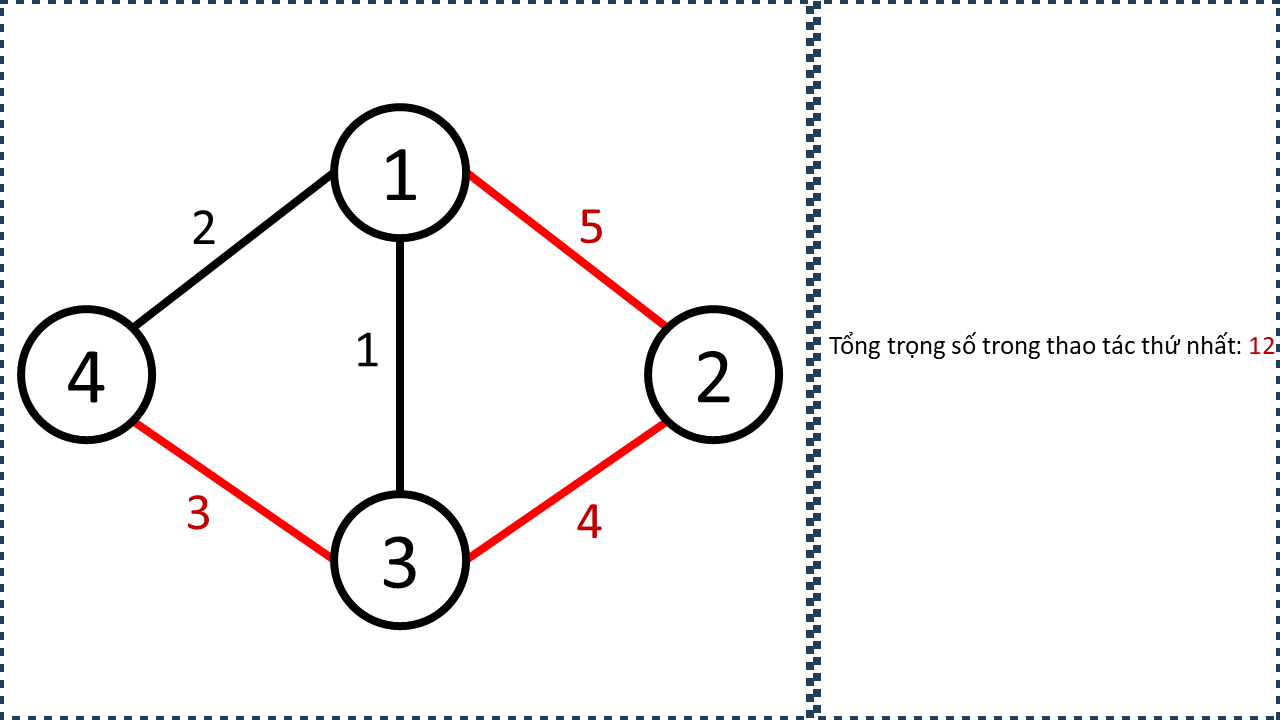
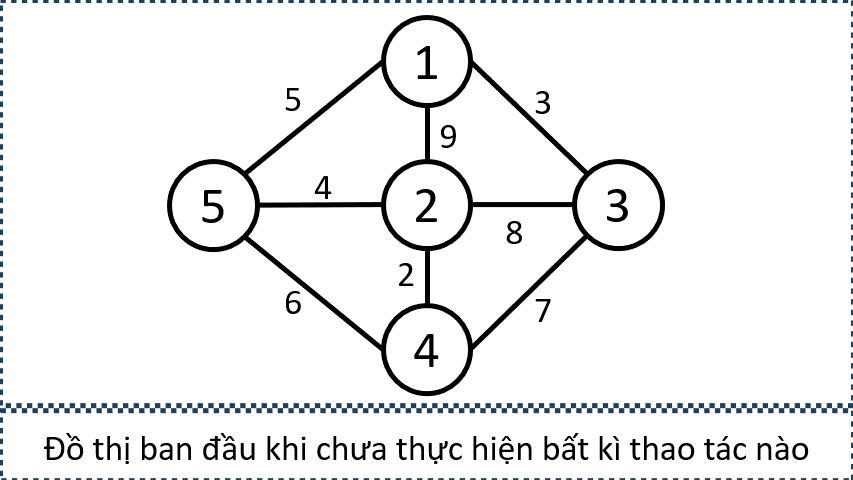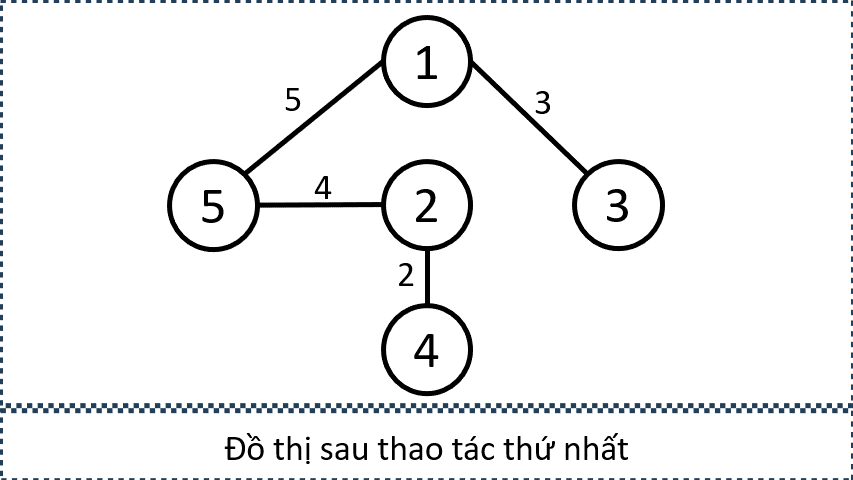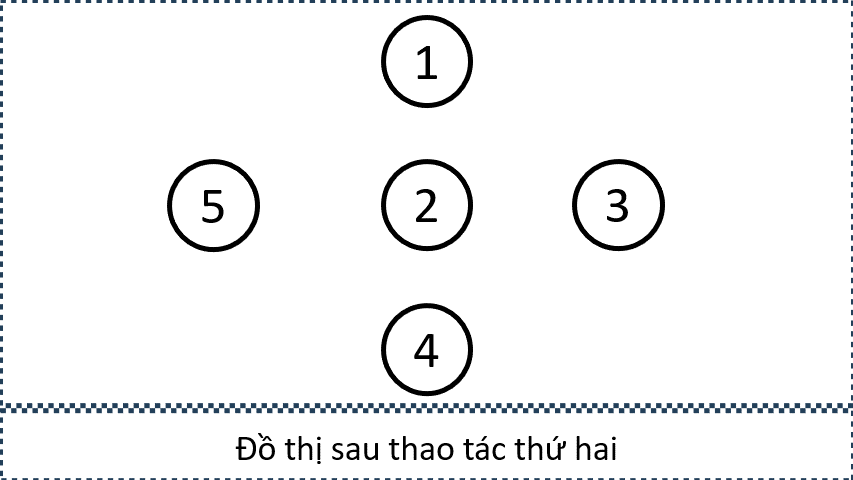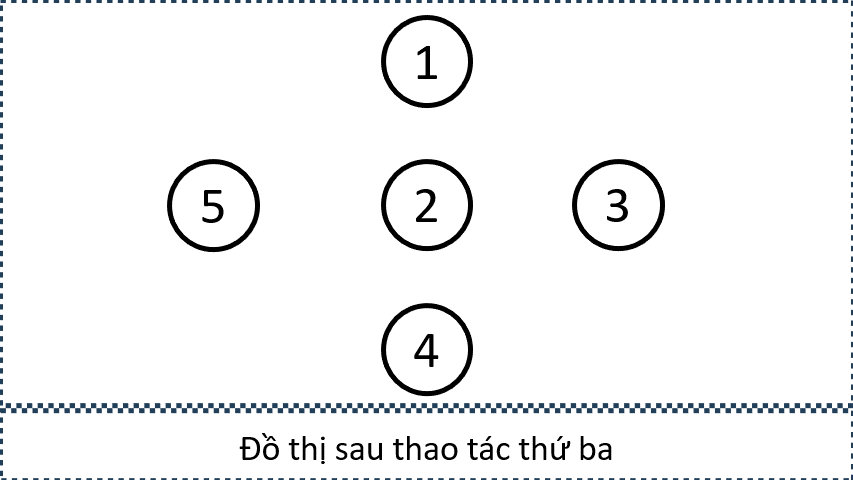
 Xét Sample Input 2 trong đề bài, từ các thông tin sau, ta có thể xây dựng đồ thị như trên:
Xét Sample Input 2 trong đề bài, từ các thông tin sau, ta có thể xây dựng đồ thị như trên: