Tạp chí VNOI số 2: Ứng dụng Kỹ thuật phân tách trọng tâm trong các truy vấn online trên cây
Ứng dụng Kỹ thuật phân tách trọng tâm trong các truy vấn online trên cây
Author:
- Nguyễn Tấn Minh - Trường Đại học Khoa học Tự nhiên - ĐHQG-HCM.
Reviewer:
- Nguyễn Minh Nhật - Georgia Institute of Technology.
- Nguyễn Tiến Mạnh - Đại học Bách khoa Hà Nội.
MỤC LỤC
Đối với các bạn đã theo đuổi Lập trình thi đấu từ lâu, có lẽ cái tên Centroid Decomposition hay Kỹ thuật phân tách trọng tâm cũng không còn xa lạ. Đây là một trong những kỹ thuật xử lý cây mạnh mẽ và phổ biến ở cấp độ các cuộc thi lớn.
Trong bài viết này, chúng mình sẽ cùng nghiên cứu một khía cạnh nhỏ của Kỹ thuật phân tách trọng tâm: ứng dụng của chúng trong việc xử lý các truy vấn online trên cây. Hiện nay tuy chưa có quá nhiều tài liệu đề cập đến vấn đề này, song đây lại là một chủ đề khá phổ biến và xuất hiện trong nhiều cuộc thi lập trình.
Lưu ý, bài viết sử dụng cơ số mặc định cho hàm ~\log~ là cơ số ~2~.
Ý tưởng chung
Nhắc lại Kỹ thuật phân tách trọng tâm
Kỹ thuật phân tách trọng tâm đã được trình bày rất chi tiết và đầy đủ tại bài viết này thuộc nền tảng VNOI Wiki. Mình xin phép nhắc lại ý tưởng chung của kỹ thuật một cách ngắn gọn như sau:
- Để xử lý bài toán trên một cây ~T~, ta đặt gốc của nó tại trọng tâm, gọi là ~C~, rồi xử lý thành phần của bài toán liên quan đến đỉnh ~C~.
- Gọi ~T_v~ là các cây con của đỉnh gốc ~C~. Ta tiếp tục xử lý đệ quy bài toán trên các cây ~T_v~.
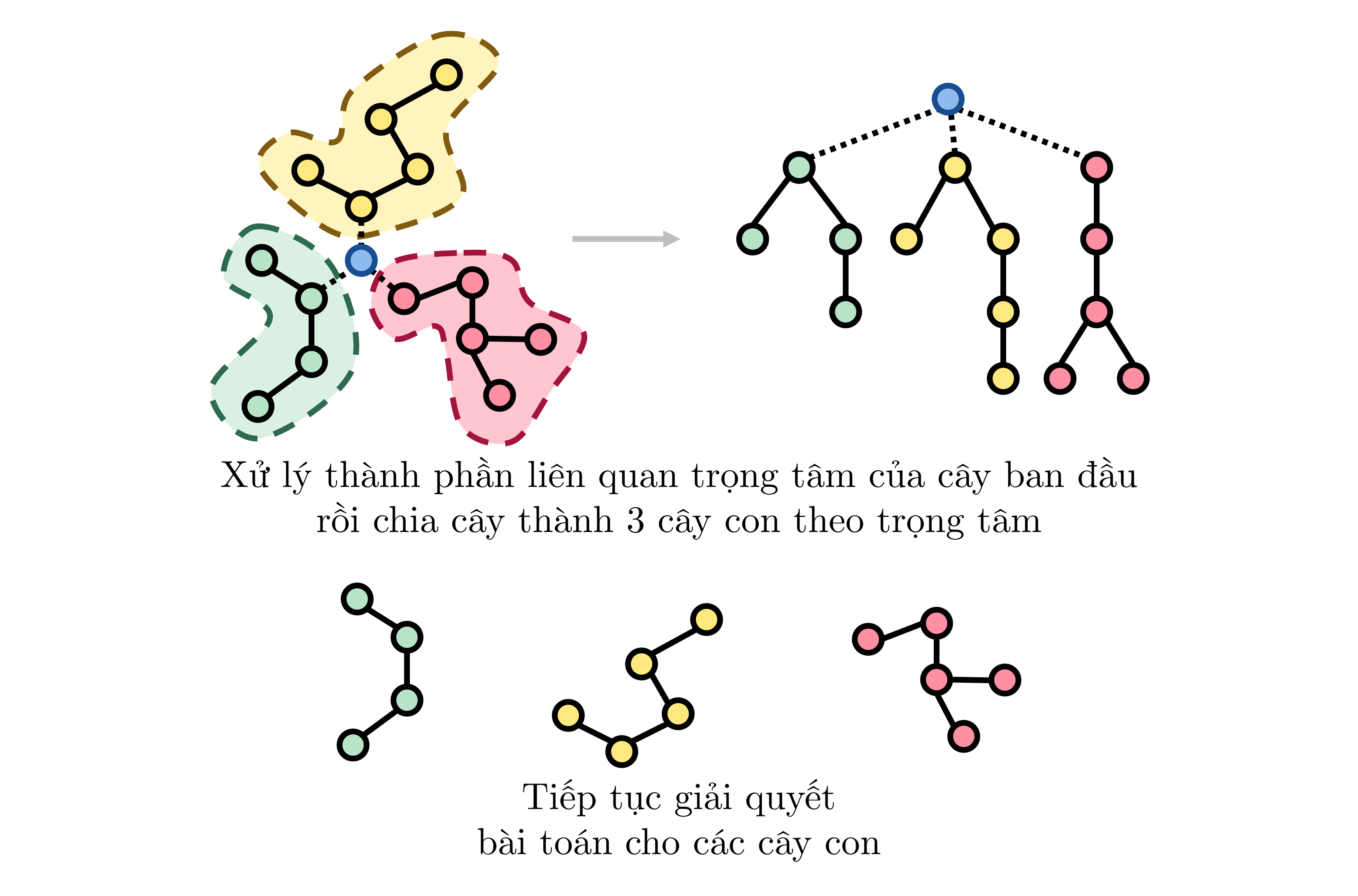
Ảnh minh họa Kỹ thuật phân tách trọng tâm
- Quá trình chia để trị được thực hiện đến khi ta được cây chỉ có ~1~ đỉnh. Khi đó ta dừng đệ quy.
Như vậy, bản chất của Kỹ thuật phân tách trọng tâm là một thuật toán Chia để trị trên cây. Ở mỗi tầng chia để trị, tổng kích thước của các cây cần được xử lý là ~\mathcal{O}(N)~ và do ta luôn chọn trọng tâm để phân tách cây nên chiều cao của cây chia để trị chỉ là ~\mathcal{O}(\log N)~.
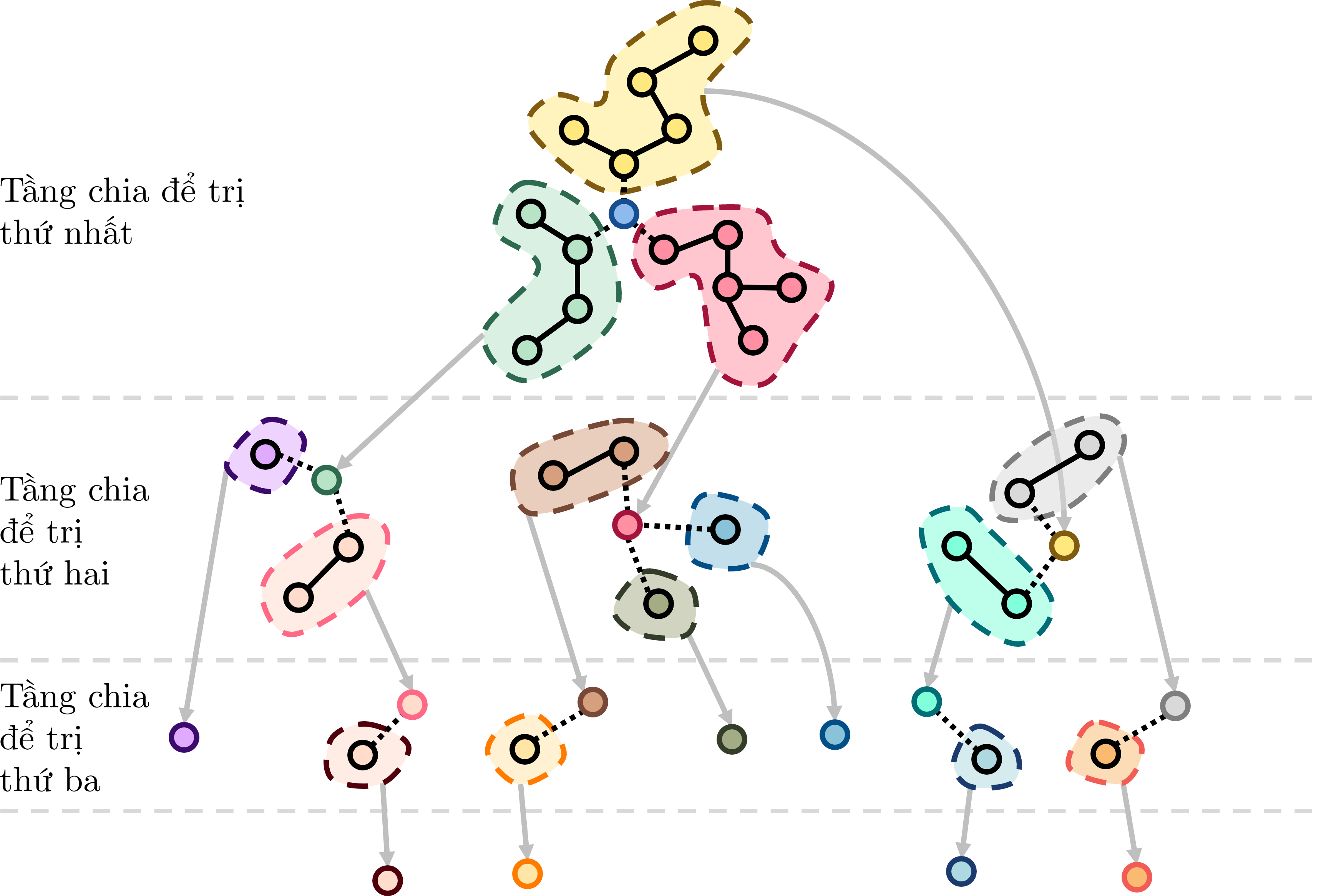
Cây chia để trị khi thực hiện Kỹ thuật phân tách trọng tâm trên cây
Thông thường khi sử dụng Kỹ thuật phân tách trọng tâm, ta sẽ duyệt cả cây chia để trị trong ~\mathcal{O}(\log N)~ nhân cho độ phức tạp để xử lý một tầng chia để trị. Tuy nhiên, trong nhiều trường hợp, ta cũng có thể sử dụng cây chia để trị này để trả lời các truy vấn online, bằng cách xây dựng trước thông tin của cây chia để trị và chỉ duyệt qua ~\mathcal{O}(\log N)~ cây con chứa thông tin liên quan đến truy vấn cần trả lời.
Bài toán mở đầu
Để nắm rõ mô hình chia để trị trên cây, chúng ta cùng nghiên cứu bài toán interactive sau:
Bài toán: Codeforces 1174F - Ehab and the Big Finale
Cho một cây gồm ~N~ đỉnh có gốc là ~1~ và một đỉnh đặc biệt ~x~ không được biết trước. Yêu cầu tìm đỉnh ~x~, sử dụng không quá ~36~ câu hỏi thuộc một trong hai dạng:
- Ta cho đỉnh ~u~, trình chấm sẽ trả về ~\texttt{dist}(u, x)~.
- Ta cho đỉnh ~u~ bắt buộc phải là tổ tiên của ~x~ và khác ~x~, trình chấm sẽ trả về đỉnh thứ hai trên đường đi từ ~u~ đến ~x~, tức đỉnh gần ~x~ nhất trong các đỉnh kề ~u~.
Giới hạn:
- ~2 \leq N \leq 2 \cdot 10^5~.
Ý tưởng
Khuyến khích bạn đọc tự giải quyết bài tập trên trước khi tiếp đến phần này
Trong bài viết này, chúng ta sẽ tập trung vào lời giải sử dụng Kỹ thuật phân tách trọng tâm (một lời giải khác sử dụng Heavy-light Decomposition).
Nhìn vào ảnh minh họa cây chia để trị của quá trình phân tách trọng tâm như trên, giả sử ta xét cây ban đầu có trọng tâm là nút màu xanh dương. Nếu có thể xác định xem đỉnh ~x~ cần tìm nằm ở đâu trong 3 cây con màu xanh lá, vàng và hồng, ta có thể chọn đi xuống cây con tương ứng trên cây chia để trị. Khi đó, số lượng đỉnh thuộc tập tìm kiếm sẽ giảm đi ít nhất một nửa.
Lặp lại quá trình tìm kiếm như vậy đến khi ta gặp một cây con có trọng tâm là đỉnh ~x~ cần tìm, hoặc gặp một nút lá trên cây chia để trị. Khi đó ta sẽ có đáp án.
Như vậy, bài toán bây giờ là xác định xem, với một cây ~T~ (là cây con của cây ban đầu) chứa ~x~, khi xóa trọng tâm ~C~ của ~T~ ra khỏi cây, ~x~ sẽ thuộc cây con nào. Tuy nhiên, các câu hỏi được đề bài cho trả về thông tin trên cây ban đầu, ta có thể đưa ra một nhận xét nhỏ rằng việc xét phạm vi của bài toán phụ trên cây ~T~ hay cả cây ban đầu là như nhau.
Một cách giải quyết bài toán phụ bằng 1 truy vấn mỗi loại là:
- Đầu tiên, ta sử dụng một truy vấn khoảng cách để xác định xem ~x~ có thuộc cây con của ~C~ hay không (xét cây con ban đầu có gốc là đỉnh ~1~). Câu trả lời là có khi và chỉ khi ~\texttt{depth}[C] + \texttt{dist}(C, x) = \texttt{dist}(1, x)~.
- Nếu ~x~ thuộc cây con của ~C~, ta có thể xác định cây con chứa ~x~ khi xóa ~C~ bằng cách hỏi đỉnh thứ hai trên đường đi từ ~C~ đến ~x~. Ta có thể đảm bảo ~C~ là tổ tiên của ~x~ trong trường hợp này.
- Ngược lại, ta có thể kết luận ngay ~x~ thuộc cây con chứa các đỉnh nằm ngoài cây con của ~C~.
Một lưu ý nhỏ là ta chỉ cần dùng 1 truy vấn khoảng cách để tính ~\texttt{dist}(1, x)~ trước khi bắt đầu chia để trị. Quá trình tìm kiếm sẽ kết thúc khi ta bắt gặp trường hợp ~\texttt{dist}(C, x) = 0~. Khi đó, đáp án cũng chính là đỉnh ~C~.
Cài đặt
Code tham khảo
#include <bits/stdc++.h>
using namespace std;
const int N = 2e5 + 5;
int depth[N], sz[N], par[N], fromRoot;
vector<int> adj[N];
bool deleted[N];
int askDistance (int u) {
cout << "d " << u << endl;
int dist; cin >> dist;
return dist;
}
int askNextNode (int u) {
cout << "s " << u << endl;
int node; cin >> node;
return node;
}
void dfsTree (int u, int p, int d) {
depth[u] = d, par[u] = p;
for (int v : adj[u])
if (v != p) dfsTree(v, u, d + 1);
}
int szDfs (int u, int p) {
sz[u] = 1;
for (int v : adj[u])
if (v != p && !deleted[v]) sz[u] += szDfs(v, u);
return sz[u];
}
int findCentroid (int u, int p, int sztr) {
for (int v : adj[u])
if (v != p && !deleted[v] && sz[v] > sztr / 2) return findCentroid(v, u, sztr);
return u;
}
int centroidDecomposition (int u) {
szDfs(u, u);
int root = findCentroid(u, u, sz[u]);
deleted[root] = true;
int dist = askDistance(root);
if (!dist) return root;
if (depth[root] + dist == fromRoot)
return centroidDecomposition(askNextNode(root));
return centroidDecomposition(par[root]);
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int N; cin >> N;
for (int i = 1; i < N; i++) {
int a, b; cin >> a >> b;
adj[a].push_back(b);
adj[b].push_back(a);
}
dfsTree(1, 1, 0);
fromRoot = askDistance(1);
int ans = centroidDecomposition(1);
cout << "! " << ans << endl;
return 0;
}
Mở rộng
Nếu đề bài yêu cầu giải bài toán nhiều lần trên cùng một cây cho trước, ta hoàn toàn có thể tách hàm trả lời ra thành hai phần. Phần đầu tiên tính trước trọng tâm của mọi cây con mà ta có thể đi qua trong quá trình chia để trị và phần thứ hai được thực hiện tương tự code tham khảo ở trên dựa trên dữ liệu đã được tính trước.
Ứng dụng trên truy vấn online trên cây
Như vậy, từ ý tưởng của bài tập interactive trên, ta cũng có thể đưa ra một mô hình áp dụng Kỹ thuật phân tách trọng tâm vào truy vấn online trên cây, dựa vào cây chia để trị được sinh ra từ quá trình sử dụng kỹ thuật này. Nhìn chung, ta sẽ chia thuật toán thành hai giai đoạn:
- Tiền xử lý (xây dựng cây chia để trị): Với tầng thứ ~\ell~ của cây chia để trị, ta tính trước ~\texttt{centroid}_\ell[u]~ là trọng tâm của cây chứa ~u~. Nếu đỉnh ~u~ đã bị xóa từ tầng chia để trị cao hơn, ta quy ước ~\texttt{centroid}_\ell[u] = 0~, xem như giá trị này không có ý nghĩa. Ngoài ra, ta có thể tính thêm các giá trị khác tùy vào nhu cầu của bước trả lời truy vấn.
- Trả lời truy vấn: Thực hiện chia để trị với thông tin từ mảng ~\texttt{centroid}_\ell[]~.
Việc cài đặt bước tiền xử lý khá giống cài đặt Centroid Decomposition thông thường:
int sz[N], centroid[LOG][N];
vector<int> adj[N];
bool removed[N];
int szDfs (int u, int p) {
sz[u] = 1;
for (int v : adj[u])
if (v != p && !removed[v]) sz[u] += szDfs(v, u);
return sz[u];
}
int findCentroid (int u, int p, int sztr) {
if (u == p) szDfs(u, u);
for (int v : adj[u])
if (v != p && !removed[v] && sz[v] > sztr / 2)
return findCentroid(v, u, sztr);
return u;
}
void dfsTree (int u, int p, int root, int level) {
centroid[level][u] = root;
// tiền xử lý các giá trị cần tính khác ở đây
// ...
for (int v : adj[u])
if (v != p && !removed[v]) dfsTree(v, u, root, level);
}
void centroidDecomposition (int u, int level = 0) {
// tìm trọng tâm của cây rồi đặt làm gốc
int root = findCentroid(u, u);
// duyệt cây với gốc mới
dfsTree(root, root, root, level);
// xóa gốc ra khỏi cây rồi duyệt tiếp các cây con
removed[root] = true;
for (int v : adj[root])
if (!removed[v]) centroidDecomposition(v, level + 1);
}
Bài tập minh họa
Để giúp bạn đọc hiểu rõ hơn về ý tưởng ứng dụng Kỹ thuật phân tách trọng tâm vào truy vấn online trên cây, ta cùng nghiên cứu hai bài toán minh họa kinh điển cho hai trường hợp truy vấn không cập nhật và có cập nhật.
Ngoài ra, để thuận tiện, chúng ta sẽ thống nhất sử dụng các ký hiệu sau cho phần còn lại của bài viết:
- ~u \rightarrow v~ hoặc ~v \rightarrow u~ là đường đi đơn giữa ~u, v~ trên cây.
- Hàm ~\texttt{centroid}(T)~ là hàm trả về một trọng tâm bất kỳ của cây ~T~.
- Hàm ~\texttt{dist}(u, v)~ là số cạnh nằm trên đường đi đơn ~u \rightarrow v~ của cây.
Truy vấn không cập nhật
Bài toán: JOI 2014 - Factories
Cho cây gồm ~N~ đỉnh có trọng số cạnh và ~Q~ truy vấn online có dạng:
- Cho hai tập đỉnh ~A, B~, tìm ~\min_{s \in A, t \in B} \texttt{dist}(s, t)~.
Giới hạn:
- ~2 \leq N \leq 5 \cdot 10^5~.
- ~1 \leq Q \leq 10^5~.
- Trọng số cạnh là các số nguyên dương không quá ~10^9~.
Ý tưởng
Khuyến khích bạn đọc tự giải quyết bài tập trên trước khi tiếp đến phần này
Như đã giới thiệu ở phần trước, ta sử dụng ý tưởng chia để trị trên cây. Gọi ~T~ là cây con đang được xử lý và ~A_T, B_T~ là tập truy vấn gồm các đỉnh thuộc cây ~T~. Ta tìm đường đi ngắn nhất giữa một cặp đỉnh ~a, b~ (với ~a \in A_T~ và ~b \in B_T~) đi qua ~C = \texttt{centroid}(T)~, các cặp đỉnh còn lại sẽ được truyền xuống các cây con của đỉnh ~C~.
Đặt gốc của cây ~T~ là đỉnh ~C~, để tính đường đi ngắn nhất cần tìm, ta chỉ cần tính với mọi đỉnh thuộc cây ~T~ một giá trị ~\texttt{depth}[u]~ là khoảng cách giữa ~u~ và đỉnh gốc ~C~. Khi đó, ta chỉ cần duyệt qua các cây con của ~T~ rồi duy trì hai biến ~\texttt{best}_A, \texttt{best}_B~ là giá trị ~\texttt{depth}[u]~ trong các đỉnh nằm trong các cây con đã duyệt.
Như vậy, khi tiền xử lý, ta chỉ cần tính các giá trị ~\texttt{depth}_\ell[u]~ là khoảng cách giữa ~u~ và đỉnh gốc ~\texttt{centroid}_\ell[u]~ tại tầng chia để trị thứ ~\ell~.
Như vậy, độ phức tạp tiền xử lý là ~\mathcal{O}(N \log N)~ và độ phức tạp cho mỗi truy vấn là ~\mathcal{O}((|A| + |B|) \log N)~ do tổng độ phức tạp tại mỗi tầng chia để trị là ~\mathcal{O}(|A| + |B|)~.
Cài đặt
Lưu ý, ta cần cài đặt khéo léo một chút để có thể duyệt các cây con của ~T~ trong ~\mathcal{O}(|A| + |B|)~. Khi đó, độ phức tạp như đã phân tích mới được đảm bảo.
Code tham khảo
#include "factories.h"
#include <bits/stdc++.h>
using namespace std;
const int N = 5e5 + 5;
vector<pair<int,int>> adj[N], container[N];
int centroid[N][21], sz[N];
long long depth[N][21];
bool removed[N];
int szDfs (int u, int p) {
sz[u] = 1;
for (auto [v, w] : adj[u])
if (!removed[v] && v != p) sz[u] += szDfs(v, u);
return sz[u];
}
int findCentroid (int u, int p, int sztr) {
for (auto [v, w] : adj[u])
if (!removed[v] && v != p && sz[v] > sztr / 2) return findCentroid(v, u, sztr);
return u;
}
void dfsTree (int u, int p, int root, int level, long long wd) {
centroid[u][level] = root, depth[u][level] = wd;
for (auto [v, w] : adj[u])
if (!removed[v] && v != p) dfsTree(v, u, root, level, wd + w);
}
void centroidDecomposition (int u, int level = 0) {
szDfs(u, u);
int root = findCentroid(u, u, sz[u]);
dfsTree(root, root, root, level, 0);
removed[root] = true;
for (auto [v, w] : adj[root])
if (!removed[v]) centroidDecomposition(v, level + 1);
}
void Init (int N, int A[], int B[], int D[]) {
for (int i = 0; i < N - 1; i++) {
adj[A[i] + 1].emplace_back(B[i] + 1, D[i]);
adj[B[i] + 1].emplace_back(A[i] + 1, D[i]);
}
centroidDecomposition(1);
}
long long Query (int S, int X[], int T, int Y[]) {
vector<pair<int,int>> initQuery;
initQuery.reserve(S + T);
for (int i = 0; i < S; i++)
initQuery.emplace_back(X[i] + 1, 0);
for (int i = 0; i < T; i++)
initQuery.emplace_back(Y[i] + 1, 1);
queue<tuple<int, vector<pair<int,int>>, int>> q;
q.emplace(centroid[1][0], initQuery, 0);
long long ans = LLONG_MAX;
while (q.size()) {
int root, level; vector<pair<int,int>> query;
tie(root, query, level) = q.front(); q.pop();
for (auto [u, type] : query) {
int node = (centroid[u][level + 1] ? centroid[u][level + 1] : root);
container[node].emplace_back(u, type);
}
long long bestA = LLONG_MAX, bestB = LLONG_MAX;
for (auto [u, tmp] : query) {
int c = (centroid[u][level + 1] ? centroid[u][level + 1] : root);
if (container[c].empty()) continue;
if (!centroid[u][level + 1] && container[c].front().second != container[c].back().second) ans = 0;
for (auto [node, type] : container[c]) {
if (type && bestA != LLONG_MAX) ans = min(ans, bestA + depth[node][level]);
if (!type && bestB != LLONG_MAX) ans = min(ans, bestB + depth[node][level]);
}
for (auto [node, type] : container[c]) {
if (type) bestB = min(bestB, depth[node][level]);
else bestA = min(bestA, depth[node][level]);
}
if (centroid[u][level + 1]) q.emplace(c, container[c], level + 1);
container[c].clear();
}
}
return ans;
}
Truy vấn có cập nhật
Bài toán
Cho cây gồm ~N~ đỉnh có trọng số đỉnh được cho bởi một dãy ~a~ và ~Q~ truy vấn online, mỗi truy vấn thuộc một trong hai loại:
- Cập nhật trọng số của một đỉnh ~v~ theo giá trị ~w~, tức gán ~a_v \leftarrow w~.
- Cho đỉnh ~u~, tìm ~\min_{v \neq u} a_v + \texttt{dist}(u, v)~ với ~\texttt{dist}(u, v)~ là số cạnh trên đường đi đơn từ ~u~ đến ~v~.
Giới hạn:
- ~1 \leq N, Q \leq 2 \cdot 10^5~.
- ~1 \leq a_v \leq 10^9~.
Trả lời truy vấn
Khuyến khích bạn đọc tự giải quyết bài tập trên trước khi tiếp đến phần này
Một lần nữa, ta sử dụng Chia để trị. Gọi ~T~ là cây con đang được xử lý có trọng tâm ~C~ tại tầng chia để trị ~\ell~, ta xét các đường đi ~u \rightarrow v~ đi qua ~C~, lưu ý rằng ~u~ là đỉnh được cố định trong truy vấn. Như vậy, với mọi cây con ~T_v~ không chứa ~u~, ta chỉ cần duy trì giá trị ~\min_{v \in T_v} a_v + \texttt{depth}_\ell[v]~ và đặt là ~\texttt{opt}_\ell(T_v)~. Khi đó, giá trị cần tính tại tầng chia để trị ~\ell~ là:
Thông thường, việc tính ~\min_{T_v \not\owns u} \texttt{opt}_\ell(T_v)~ sẽ cần đến một cấu trúc dữ liệu hỗ trợ. Tuy nhiên, ta có thể đưa ra nhận xét rằng việc bỏ đi điều kiện ~T_v \not\owns u~ sẽ không làm ảnh hưởng đáp án cuối cùng. Lý do là vì nếu cây con ~T_v \owns u~ được chọn trong hàm ~\min~, điều đó cũng tương đương với việc ta đang chọn một đường đi qua một cạnh nào đó nhiều hơn ~1~ lần. Khi đó, luôn tồn tại một phương án hợp lệ và có chi phí thấp hơn để thay thế khi ta tiếp tục chia để trị xuống cây ~T_v~ đó.
Như vậy, ta chỉ cần tính:
Sau đó, ta tiếp tục chia để trị xuống cây con ~T_v~ chứa ~u~.
Cập nhật
Với công thức rút gọn như trên, với mỗi cây con, ta chỉ cần tính ~\texttt{opt}(T) = \min_{v \in T} (a_v + \texttt{depth}_\ell[v])~. Lúc này, ta cũng không cần quan tâm tầng chia để trị ~\ell~ nữa. Hơn nữa, để tiện cho phần cài đặt, ta có thể sử dụng chính chỉ số của trọng tâm ~\texttt{centroid}(T)~ để đánh số cho các cây ~T~ trong quá trình duyệt.
Như vậy, ta định nghĩa lại mảng ~\texttt{opt}[]~ như sau:
Với ~T~ là cây nhận ~C~ làm trọng tâm.
Lúc này, do mỗi nút chỉ được chọn làm trọng tâm đúng một lần trên cả cây chia để trị, ta không cần dùng tham số ~\ell~ để phân biệt các tầng chia để trị nữa.
Để cập nhật một giá trị ~a_v~, ta cần cập nhật các giá trị ~\texttt{opt}[C]~ cho các cây nằm trên đường đi xuống nút ~v~ trên cây chia để trị. Việc cập nhật có thể được thực hiện cùng với một cấu trúc dữ liệu có sẵn như priority_queue hoặc multiset.
Như vậy, ta có độ phức tạp ~\mathcal{O}(\log^2 N)~ cho mỗi phép cập nhật và ~\mathcal{O}(\log N)~ cho mỗi phép trả lời truy vấn, do ta có thể lấy phần tử nhỏ nhất từ một priority_queue hoặc multiset trong ~\mathcal{O}(1)~.
Cài đặt
Với đặc thù của các truy vấn được nêu trong bài toán, ta hoàn toàn có thể chỉ sử dụng đệ quy trong bước tiền xử lý và khử đệ quy khi trả lời truy vấn.
Code tham khảo
Tiền xử lý:int a[N], sz[N], centroid[N][18], depth[N][18];
vector<int> adj[N];
bool deleted[N];
int szDfs (int u, int p) {
sz[u] = 1;
for (int v : adj[u])
if (v != p && !deleted[v]) sz[u] += szDfs(v, u);
return sz[u];
}
int findCentroid (int u, int p, int sztr) {
for (int v : adj[u])
if (v != p && !deleted[v] && sz[v] > sztr / 2) return findCentroid(v, u, sztr);
return u;
}
void dfsTree (int u, int p, int root, int d, int level) {
centroid[u][level] = root, depth[u][level] = d;
pq[root].emplace(a[u] + depth[u][level], u);
for (int v : adj[u])
if (v != p && !deleted[v]) dfsTree(v, u, root, d + 1, level);
}
void centroidDecomposition (int u, int level = 0) {
szDfs(u, u);
int root = findCentroid(u, u, sz[u]);
dfsTree(root, root, root, 0, level);
deleted[root] = true;
for (int v : adj[root])
if (!deleted[v]) centroidDecomposition(v, level + 1);
}
Xử lý các truy vấn:
using pii = pair<int,int>;
priority_queue<pii, vector<pii>, greater<pii>> pq[N];
void refineQueue (int root, int level, int eliminateAll = -1) {
while (pq[root].size()) {
int val, node; tie(val, node) = pq[root].top();
if (val != a[node] + depth[node][level] || node == eliminateAll) pq[root].pop();
else return;
}
}
int getExcept (int root, int level, int except) {
refineQueue(root, level);
if (pq[root].empty()) return INT_MAX;
if (pq[root].top().second == except) {
pii hold = pq[root].top(); pq[root].pop();
refineQueue(root, level, except);
int ans = pq[root].size() ? pq[root].top().first : INT_MAX;
return pq[root].push(hold), ans;
}
return pq[root].top().first;
}
void updateWeight (int v, int w) {
a[v] = w;
for (int level = 0; centroid[v][level]; level++) {
int root = centroid[v][level];
pq[root].emplace(a[v] + depth[v][level], v);
}
}
int query (int u) {
int ans = INT_MAX;
for (int level = 0; centroid[u][level]; level++) {
int root = centroid[u][level], curr = getExcept(root, level, u);
if (curr != INT_MAX) ans = min(ans, curr + depth[u][level]);
}
return ans;
}
Lưu ý, với cách cài đặt như trên, mỗi lần gọi truy vấn có thể kéo theo các thao tác pop trên priority_queue, khi này độ phức tạp của hàm trên thực tế không phải là ~\mathcal{O}(\log N)~ nữa. Tuy nhiên, số lần thực hiện thao tác pop phụ thuộc vào số thao tác cập nhật trước đó, nên ta có thể xem như độ phức tạp được gây ra bởi thao tác pop được tính cho hàm cập nhật chứ không phải hàm truy vấn.
Phụ lục
Tài liệu tham khảo
- Cao Thanh Hậu. Thuật toán phân tách trọng tâm - Centroid Decomposition (VNOI Wiki).
- Siyong Huang, Benjamin Qi. Centroid Decomposition (USACO Guide).
- Robert. A Simple Introduction to Centroid Decomposition.
Bình luận